Tsai Richard Tzong-Han, Chou Wen-Chi, Su Ying-Shan, Lin Yu-Chun, Sung Cheng-Lung, Dai Hong-Jie, Yeh Irene Tzu-Hsuan, Ku Wei, Sung Ting-Yi, Hsu Wen-Lian
Institute of Information Science, Academia Sinica, Nankang, Taipei 115, Taiwan, PRoC.
BMC Bioinformatics. 2007 Sep 1;8:325. doi: 10.1186/1471-2105-8-325.
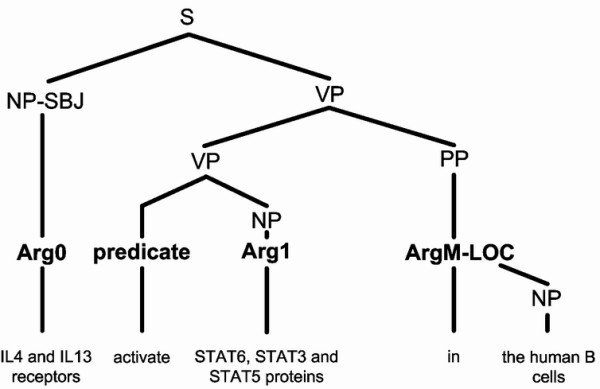
Bioinformatics tools for automatic processing of biomedical literature are invaluable for both the design and interpretation of large-scale experiments. Many information extraction (IE) systems that incorporate natural language processing (NLP) techniques have thus been developed for use in the biomedical field. A key IE task in this field is the extraction of biomedical relations, such as protein-protein and gene-disease interactions. However, most biomedical relation extraction systems usually ignore adverbial and prepositional phrases and words identifying location, manner, timing, and condition, which are essential for describing biomedical relations. Semantic role labeling (SRL) is a natural language processing technique that identifies the semantic roles of these words or phrases in sentences and expresses them as predicate-argument structures. We construct a biomedical SRL system called BIOSMILE that uses a maximum entropy (ME) machine-learning model to extract biomedical relations. BIOSMILE is trained on BioProp, our semi-automatic, annotated biomedical proposition bank. Currently, we are focusing on 30 biomedical verbs that are frequently used or considered important for describing molecular events.
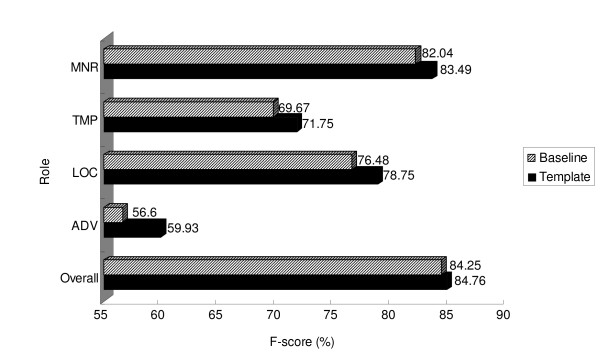
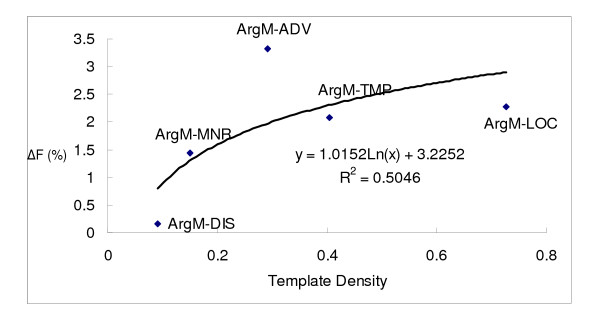
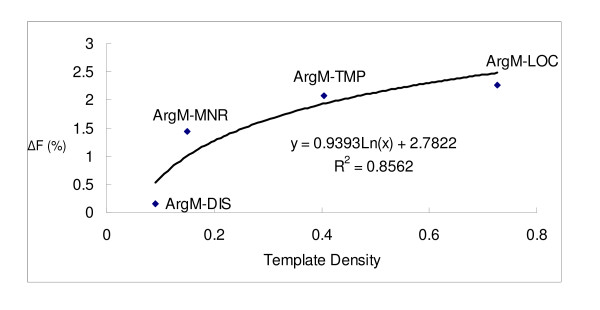
To evaluate the performance of BIOSMILE, we conducted two experiments to (1) compare the performance of SRL systems trained on newswire and biomedical corpora; and (2) examine the effects of using biomedical-specific features. The experimental results show that using BioProp improves the F-score of the SRL system by 21.45% over an SRL system that uses a newswire corpus. It is noteworthy that adding automatically generated template features improves the overall F-score by a further 0.52%. Specifically, ArgM-LOC, ArgM-MNR, and Arg2 achieve statistically significant performance improvements of 3.33%, 2.27%, and 1.44%, respectively.
We demonstrate the necessity of using a biomedical proposition bank for training SRL systems in the biomedical domain. Besides the different characteristics of biomedical and newswire sentences, factors such as cross-domain framesets and verb usage variations also influence the performance of SRL systems. For argument classification, we find that NE (named entity) features indicating if the target node matches with NEs are not effective, since NEs may match with a node of the parsing tree that does not have semantic role labels in the training set. We therefore incorporate templates composed of specific words, NE types, and POS tags into the SRL system. As a result, the classification accuracy for adjunct arguments, which is especially important for biomedical SRL, is improved significantly.
用于自动处理生物医学文献的生物信息学工具对于大规模实验的设计和解释都非常重要。因此,许多结合了自然语言处理(NLP)技术的信息提取(IE)系统已被开发用于生物医学领域。该领域的一项关键IE任务是提取生物医学关系,例如蛋白质-蛋白质和基因-疾病相互作用。然而,大多数生物医学关系提取系统通常会忽略状语和介词短语以及表示位置、方式、时间和条件的词,而这些对于描述生物医学关系至关重要。语义角色标注(SRL)是一种自然语言处理技术,可识别句子中这些词或短语的语义角色,并将它们表示为谓词-论元结构。我们构建了一个名为BIOSMILE的生物医学SRL系统,该系统使用最大熵(ME)机器学习模型来提取生物医学关系。BIOSMILE在BioProp(我们的半自动注释生物医学命题库)上进行训练。目前,我们专注于30个经常使用或被认为对描述分子事件很重要的生物医学动词。
为了评估BIOSMILE的性能,我们进行了两项实验,以(1)比较在新闻专线和生物医学语料库上训练的SRL系统的性能;以及(2)检查使用生物医学特定特征的效果。实验结果表明,与使用新闻专线语料库的SRL系统相比,使用BioProp可使SRL系统的F值提高21.45%。值得注意的是,添加自动生成的模板特征可使整体F值进一步提高0.52%。具体而言,ArgM-LOC、ArgM-MNR和Arg2的性能分别实现了3.