School of Computer Science, University of Manchester, Oxford Road, Manchester, M13 9PL, UK.
BMC Bioinformatics. 2011 Oct 12;12:397. doi: 10.1186/1471-2105-12-397.
Due to the rapidly expanding body of biomedical literature, biologists require increasingly sophisticated and efficient systems to help them to search for relevant information. Such systems should account for the multiple written variants used to represent biomedical concepts, and allow the user to search for specific pieces of knowledge (or events) involving these concepts, e.g., protein-protein interactions. Such functionality requires access to detailed information about words used in the biomedical literature. Existing databases and ontologies often have a specific focus and are oriented towards human use. Consequently, biological knowledge is dispersed amongst many resources, which often do not attempt to account for the large and frequently changing set of variants that appear in the literature. Additionally, such resources typically do not provide information about how terms relate to each other in texts to describe events.
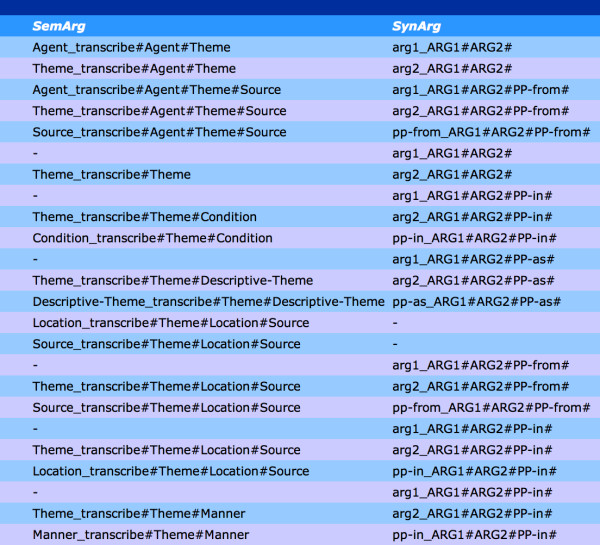
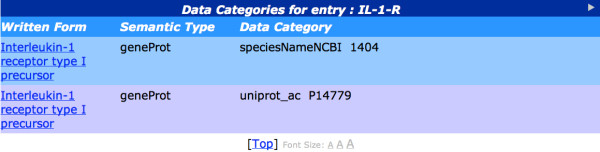
This article provides an overview of the design, construction and evaluation of a large-scale lexical and conceptual resource for the biomedical domain, the BioLexicon. The resource can be exploited by text mining tools at several levels, e.g., part-of-speech tagging, recognition of biomedical entities, and the extraction of events in which they are involved. As such, the BioLexicon must account for real usage of words in biomedical texts. In particular, the BioLexicon gathers together different types of terms from several existing data resources into a single, unified repository, and augments them with new term variants automatically extracted from biomedical literature. Extraction of events is facilitated through the inclusion of biologically pertinent verbs (around which events are typically organized) together with information about typical patterns of grammatical and semantic behaviour, which are acquired from domain-specific texts. In order to foster interoperability, the BioLexicon is modelled using the Lexical Markup Framework, an ISO standard.
The BioLexicon contains over 2.2 M lexical entries and over 1.8 M terminological variants, as well as over 3.3 M semantic relations, including over 2 M synonymy relations. Its exploitation can benefit both application developers and users. We demonstrate some such benefits by describing integration of the resource into a number of different tools, and evaluating improvements in performance that this can bring.
由于生物医学文献数量的快速增长,生物学家需要越来越复杂和高效的系统来帮助他们搜索相关信息。这些系统应该考虑到用于表示生物医学概念的多种书写变体,并允许用户搜索涉及这些概念的特定知识(或事件),例如蛋白质-蛋白质相互作用。此类功能需要访问生物医学文献中使用的单词的详细信息。现有的数据库和本体通常具有特定的重点,并且面向人类使用。因此,生物知识分散在许多资源中,这些资源通常不试图解释文献中出现的大量且经常变化的变体集。此外,此类资源通常不提供有关术语在描述事件的文本中相互关联的信息。
本文概述了大规模生物医学领域词汇和概念资源——BioLexicon 的设计、构建和评估。该资源可在多个级别上被文本挖掘工具利用,例如词性标注、生物医学实体识别以及它们所涉及的事件提取。因此,BioLexicon 必须考虑生物医学文本中单词的实际用法。特别是,BioLexicon 将来自几个现有数据资源的不同类型的术语汇集到一个单一的统一存储库中,并使用从生物医学文献中自动提取的新术语变体对其进行扩充。通过包含通常围绕事件组织的生物相关动词以及从领域特定文本中获取的关于语法和语义行为典型模式的信息,促进了事件的提取。为了促进互操作性,BioLexicon 使用 Lexical Markup Framework(ISO 标准)进行建模。
BioLexicon 包含超过 220 万个词汇条目和超过 1800 万个术语变体,以及超过 3300 万语义关系,包括超过 200 万个同义词关系。它的利用可以使应用程序开发人员和用户都受益。我们通过描述将该资源集成到许多不同工具中,并评估这可以带来的性能改进,来展示一些这样的好处。