Zhang C, Crasta O, Cammer S, Will R, Kenyon R, Sullivan D, Yu Q, Sun W, Jha R, Liu D, Xue T, Zhang Y, Moore M, McGarvey P, Huang H, Chen Y, Zhang J, Mazumder R, Wu C, Sobral B
Virginia Bioinformatics Institute at Virginia Polytechnic Institute and State University, Washington Street (0477), Blacksburg, VA 24061, USA.
Nucleic Acids Res. 2008 Jan;36(Database issue):D884-91. doi: 10.1093/nar/gkm903. Epub 2007 Nov 4.
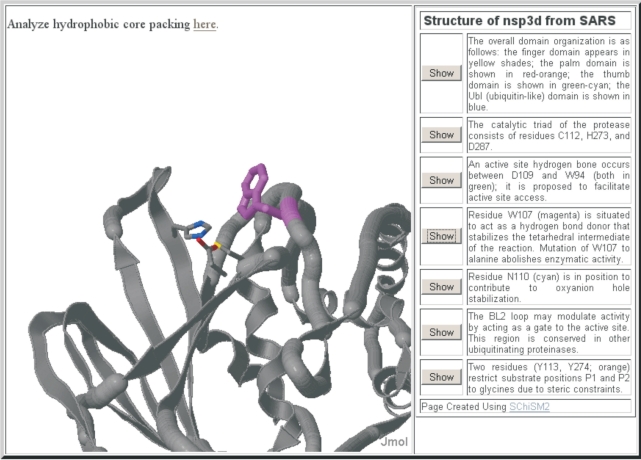
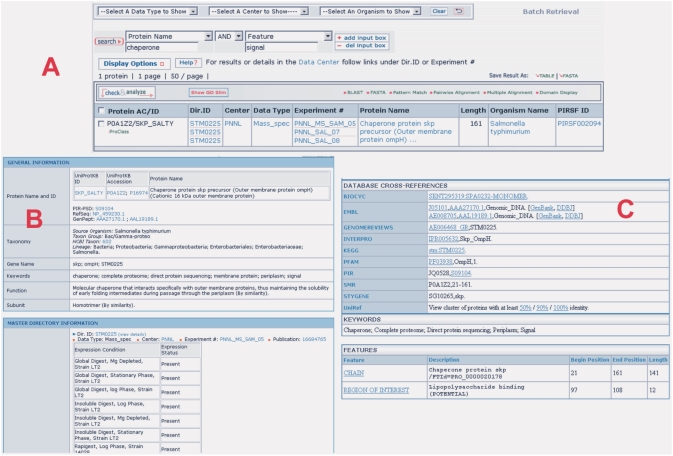
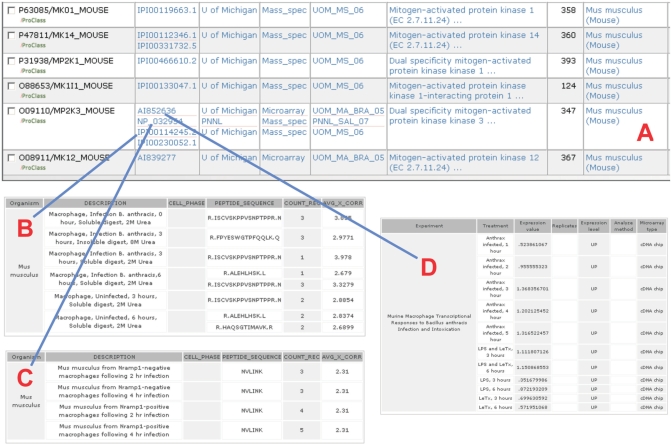
The NIAID-funded Biodefense Proteomics Resource Center (RC) provides storage, dissemination, visualization and analysis capabilities for the experimental data deposited by seven Proteomics Research Centers (PRCs). The data and its publication is to support researchers working to discover candidates for the next generation of vaccines, therapeutics and diagnostics against NIAID's Category A, B and C priority pathogens. The data includes transcriptional profiles, protein profiles, protein structural data and host-pathogen protein interactions, in the context of the pathogen life cycle in vivo and in vitro. The database has stored and supported host or pathogen data derived from Bacillus, Brucella, Cryptosporidium, Salmonella, SARS, Toxoplasma, Vibrio and Yersinia, human tissue libraries, and mouse macrophages. These publicly available data cover diverse data types such as mass spectrometry, yeast two-hybrid (Y2H), gene expression profiles, X-ray and NMR determined protein structures and protein expression clones. The growing database covers over 23 000 unique genes/proteins from different experiments and organisms. All of the genes/proteins are annotated and integrated across experiments using UniProt Knowledgebase (UniProtKB) accession numbers. The web-interface for the database enables searching, querying and downloading at the level of experiment, group and individual gene(s)/protein(s) via UniProtKB accession numbers or protein function keywords. The system is accessible at http://www.proteomicsresource.org/.
美国国立过敏与传染病研究所(NIAID)资助的生物防御蛋白质组学资源中心(RC)为七个蛋白质组学研究中心(PRC)所存储的实验数据提供存储、传播、可视化及分析功能。这些数据及其出版物旨在支持研究人员致力于发现针对NIAID的A、B、C类优先病原体的下一代疫苗、治疗方法及诊断方法的候选物。数据包括转录谱、蛋白质谱、蛋白质结构数据以及宿主-病原体蛋白质相互作用,涵盖病原体在体内和体外生命周期的相关内容。该数据库已存储并支持源自芽孢杆菌、布鲁氏菌、隐孢子虫、沙门氏菌、非典病毒、弓形虫、弧菌和耶尔森氏菌、人体组织库以及小鼠巨噬细胞的宿主或病原体数据。这些公开可用的数据涵盖多种数据类型,如质谱分析、酵母双杂交(Y2H)、基因表达谱、X射线和核磁共振确定的蛋白质结构以及蛋白质表达克隆。不断增长的数据库涵盖来自不同实验和生物体的超过23000个独特基因/蛋白质。所有基因/蛋白质均使用UniProt知识库(UniProtKB)登录号进行注释并跨实验整合。该数据库的网络界面支持通过UniProtKB登录号或蛋白质功能关键词在实验、组以及单个基因/蛋白质层面进行搜索、查询和下载。可通过http://www.proteomicsresource.org/访问该系统。