Touzet Hélène, Varré Jean-Stéphane
LIFL, UMR CNRS 8022, Université des Sciences et Technologies de Lille, 59655 Villeneuve d'Ascq, France.
Algorithms Mol Biol. 2007 Dec 11;2:15. doi: 10.1186/1748-7188-2-15.
Position Weight Matrices (PWMs) are probabilistic representations of signals in sequences. They are widely used to model approximate patterns in DNA or in protein sequences. The usage of PWMs needs as a prerequisite to knowing the statistical significance of a word according to its score. This is done by defining the P-value of a score, which is the probability that the background model can achieve a score larger than or equal to the observed value. This gives rise to the following problem: Given a P-value, find the corresponding score threshold. Existing methods rely on dynamic programming or probability generating functions. For many examples of PWMs, they fail to give accurate results in a reasonable amount of time.
The contribution of this paper is two fold. First, we study the theoretical complexity of the problem, and we prove that it is NP-hard. Then, we describe a novel algorithm that solves the P-value problem efficiently. The main idea is to use a series of discretized score distributions that improves the final result step by step until some convergence criterion is met. Moreover, the algorithm is capable of calculating the exact P-value without any error, even for matrices with non-integer coefficient values. The same approach is also used to devise an accurate algorithm for the reverse problem: finding the P-value for a given score. Both methods are implemented in a software called TFM-PVALUE, that is freely available.
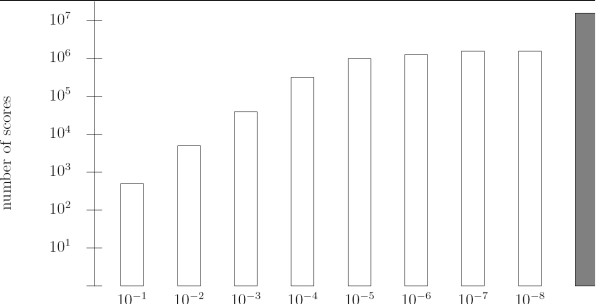
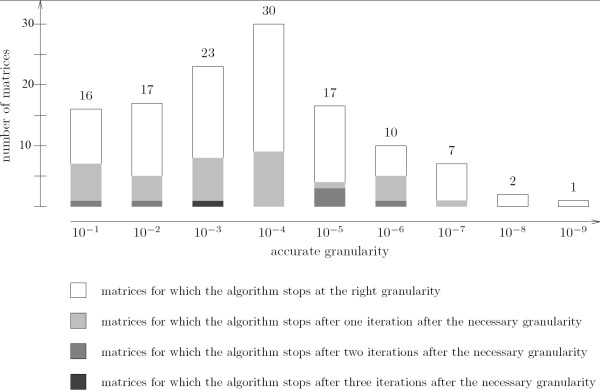
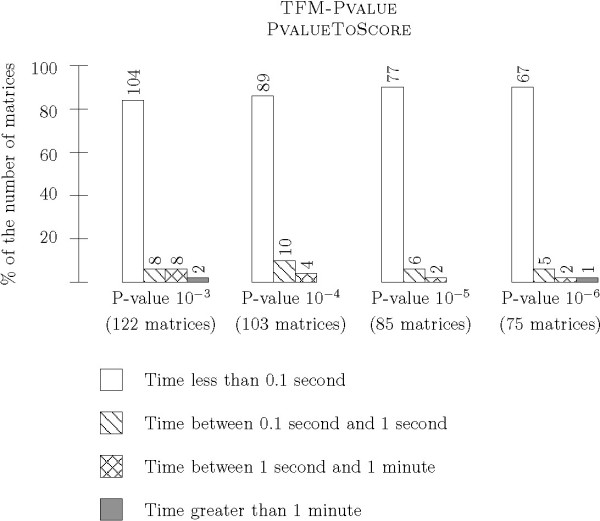
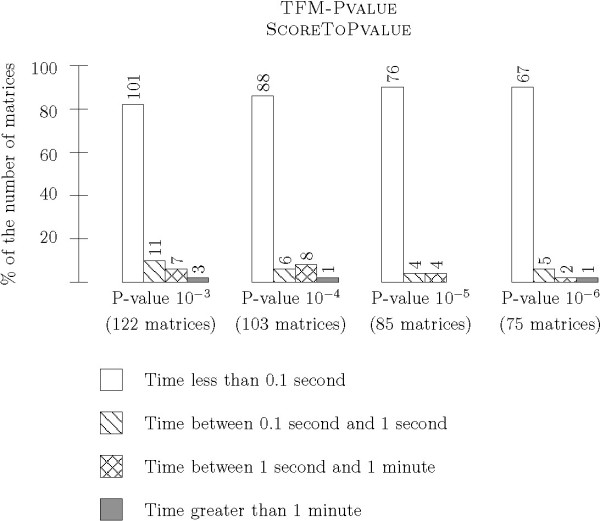
We have tested TFM-PVALUE on a large set of PWMs representing transcription factor binding sites. Experimental results show that it achieves better performance in terms of computational time and precision than existing tools.
位置权重矩阵(PWMs)是序列中信号的概率表示。它们被广泛用于对DNA或蛋白质序列中的近似模式进行建模。使用PWMs需要预先知道一个单词根据其得分的统计显著性。这是通过定义得分的P值来完成的,P值是背景模型能够获得大于或等于观测值的得分的概率。这就产生了以下问题:给定一个P值,找到相应的得分阈值。现有方法依赖于动态规划或概率生成函数。对于许多PWMs的例子,它们在合理的时间内无法给出准确的结果。
本文的贡献有两个方面。首先,我们研究了该问题的理论复杂度,并证明它是NP难的。然后,我们描述了一种能有效解决P值问题的新算法。主要思想是使用一系列离散化的得分分布,逐步改进最终结果,直到满足某个收敛标准。此外,该算法能够精确计算P值,没有任何误差,即使对于系数值为非整数的矩阵也是如此。同样的方法也被用于设计一个精确的算法来解决反向问题:为给定的得分找到P值。这两种方法都在一个名为TFM-PVALUE的软件中实现,该软件可免费获取。
我们在一大组表示转录因子结合位点的PWMs上测试了TFM-PVALUE。实验结果表明,与现有工具相比,它在计算时间和精度方面都有更好的性能。