Wang Shijun, Szalay Máté S, Zhang Changshui, Csermely Peter
Department of Automation, Tsinghua University, Beijing, China.
PLoS One. 2008 Apr 9;3(4):e1917. doi: 10.1371/journal.pone.0001917.
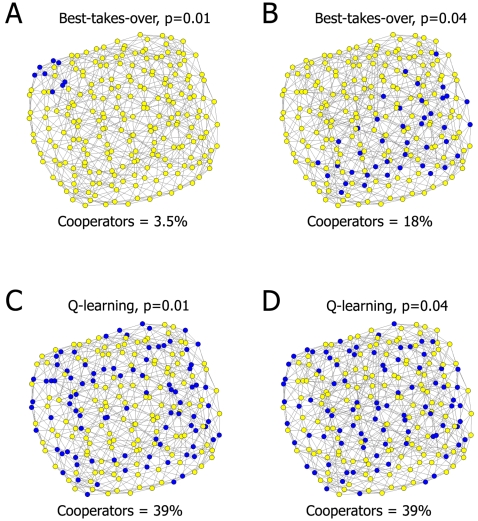
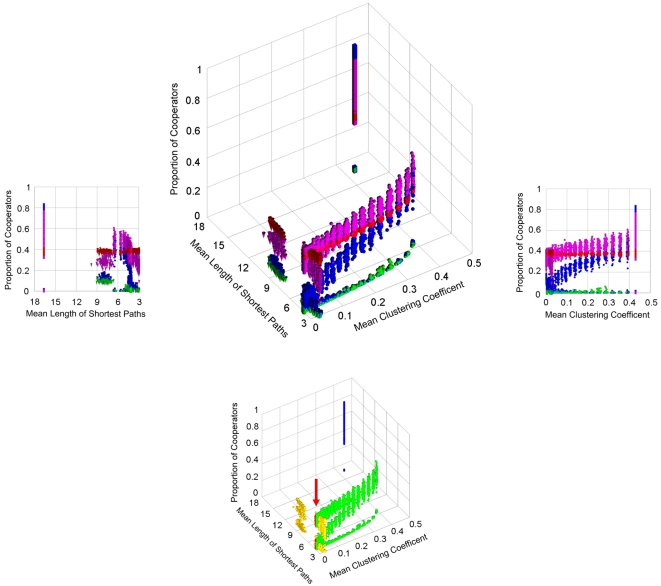
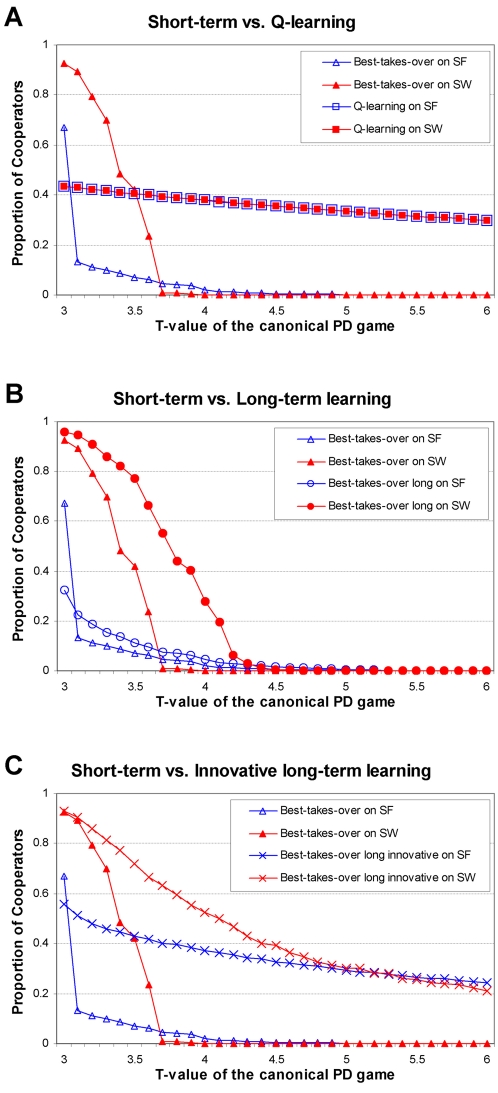
Cooperation plays a key role in the evolution of complex systems. However, the level of cooperation extensively varies with the topology of agent networks in the widely used models of repeated games. Here we show that cooperation remains rather stable by applying the reinforcement learning strategy adoption rule, Q-learning on a variety of random, regular, small-word, scale-free and modular network models in repeated, multi-agent Prisoner's Dilemma and Hawk-Dove games. Furthermore, we found that using the above model systems other long-term learning strategy adoption rules also promote cooperation, while introducing a low level of noise (as a model of innovation) to the strategy adoption rules makes the level of cooperation less dependent on the actual network topology. Our results demonstrate that long-term learning and random elements in the strategy adoption rules, when acting together, extend the range of network topologies enabling the development of cooperation at a wider range of costs and temptations. These results suggest that a balanced duo of learning and innovation may help to preserve cooperation during the re-organization of real-world networks, and may play a prominent role in the evolution of self-organizing, complex systems.
合作在复杂系统的演化中起着关键作用。然而,在广泛使用的重复博弈模型中,合作水平会因主体网络的拓扑结构而有很大差异。在此我们表明,通过应用强化学习策略采用规则,即在重复的多主体囚徒困境和鹰鸽博弈中,在各种随机、规则、小世界、无标度和模块化网络模型上进行Q学习,合作能保持相当稳定。此外,我们发现使用上述模型系统,其他长期学习策略采用规则也能促进合作,而在策略采用规则中引入低水平噪声(作为创新模型)会使合作水平降低对实际网络拓扑结构的依赖。我们的结果表明,策略采用规则中的长期学习和随机因素共同作用时,能扩展网络拓扑结构的范围,从而在更广泛的成本和诱惑范围内促进合作的发展。这些结果表明,学习与创新的平衡组合可能有助于在现实世界网络重组过程中维持合作,并可能在自组织复杂系统的演化中发挥重要作用。