Kim Sun, Shin Soo-Yong, Lee In-Hee, Kim Soo-Jin, Sriram Ram, Zhang Byoung-Tak
Biointelligence Laboratory, School of Computer Science and Engineering, Seoul National University, Seoul 151-744, Korea.
Nucleic Acids Res. 2008 Jul 1;36(Web Server issue):W411-5. doi: 10.1093/nar/gkn281. Epub 2008 May 28.
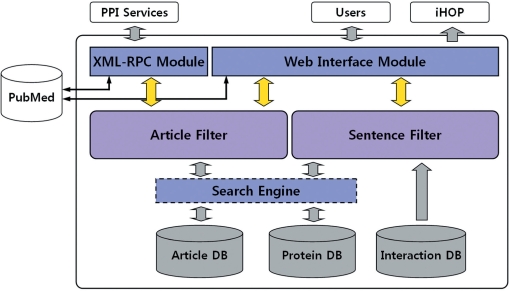
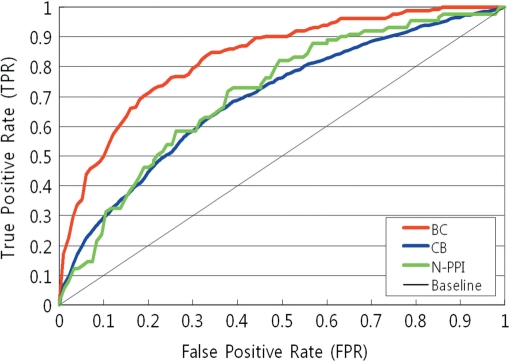
Protein-protein interaction (PPI) extraction has been an important research topic in bio-text mining area, since the PPI information is critical for understanding biological processes. However, there are very few open systems available on the Web and most of the systems focus on keyword searching based on predefined PPIs. PIE (Protein Interaction information Extraction system) is a configurable Web service to extract PPIs from literature, including user-provided papers as well as PubMed articles. After providing abstracts or papers, the prediction results are displayed in an easily readable form with essential, yet compact features. The PIE interface supports more features such as PDF file extraction, PubMed search tool and network communication, which are useful for biologists and bio-system developers. The PIE system utilizes natural language processing techniques and machine learning methodologies to predict PPI sentences, which results in high precision performance for Web users. PIE is freely available at http://bi.snu.ac.kr/pie/.
蛋白质-蛋白质相互作用(PPI)提取一直是生物文本挖掘领域的一个重要研究课题,因为PPI信息对于理解生物过程至关重要。然而,网络上可用的开放系统非常少,并且大多数系统专注于基于预定义PPI的关键词搜索。PIE(蛋白质相互作用信息提取系统)是一个可配置的网络服务,用于从文献中提取PPI,包括用户提供的论文以及PubMed文章。在提供摘要或论文后,预测结果会以易于阅读的形式显示,具有重要但简洁的特征。PIE界面支持更多功能,如PDF文件提取、PubMed搜索工具和网络通信,这些对生物学家和生物系统开发者很有用。PIE系统利用自然语言处理技术和机器学习方法来预测PPI句子,这为网络用户带来了高精度的性能。可在http://bi.snu.ac.kr/pie/免费获取PIE。