von der Haar Tobias
Protein Science Group, Department of Biosciences, University of Kent, Canterbury, CT2 7NJ, UK.
BMC Syst Biol. 2008 Oct 16;2:87. doi: 10.1186/1752-0509-2-87.
Translation of messenger mRNAs makes significant contributions to the control of gene expression in all eukaryotes. Because translational control often involves fractional changes in translational activity, good quantitative descriptions of translational activity will be required to achieve a comprehensive understanding of this aspect of biology. Data on translational activity are difficult to generate experimentally under physiological conditions, however, translational activity as a parameter is in principle accessible through published genome-wide datasets.
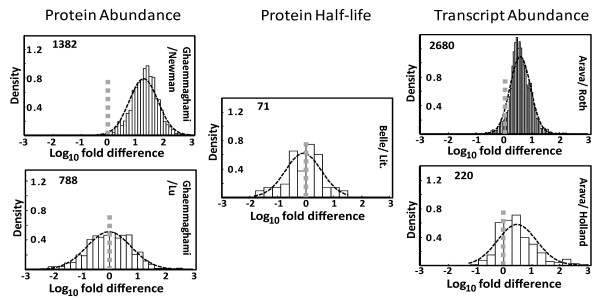
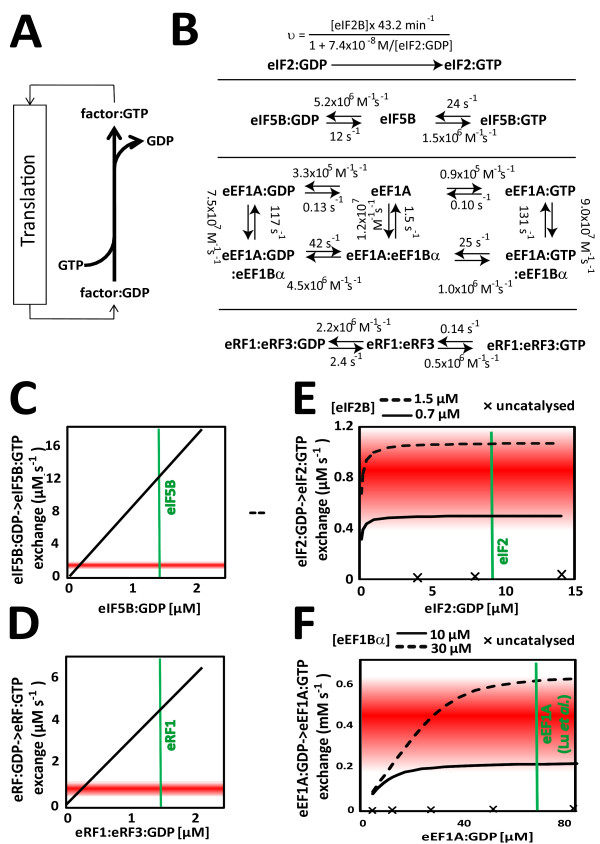
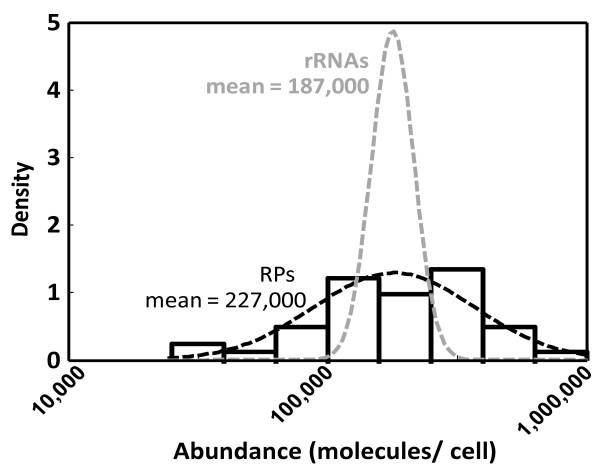
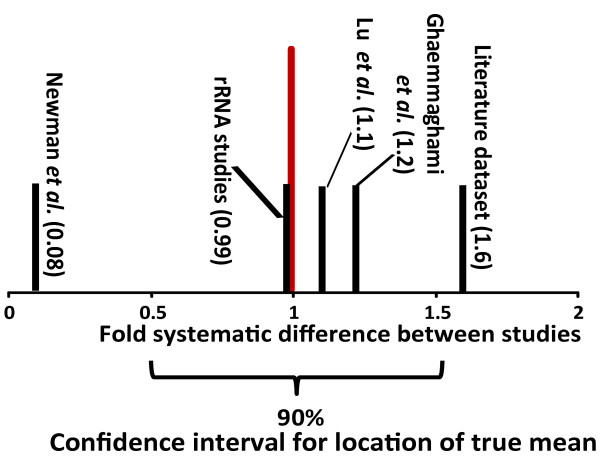
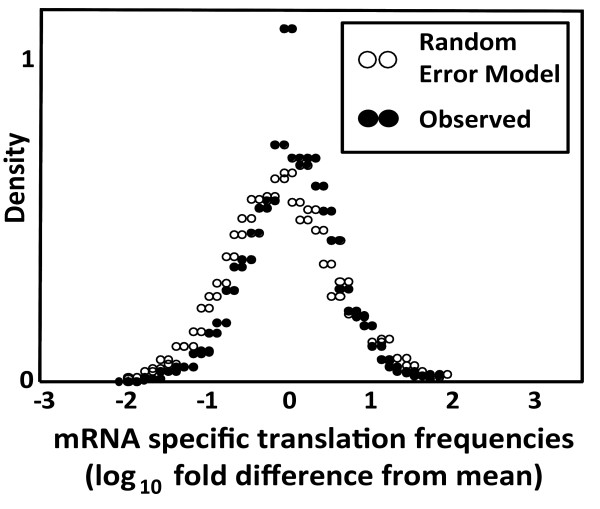
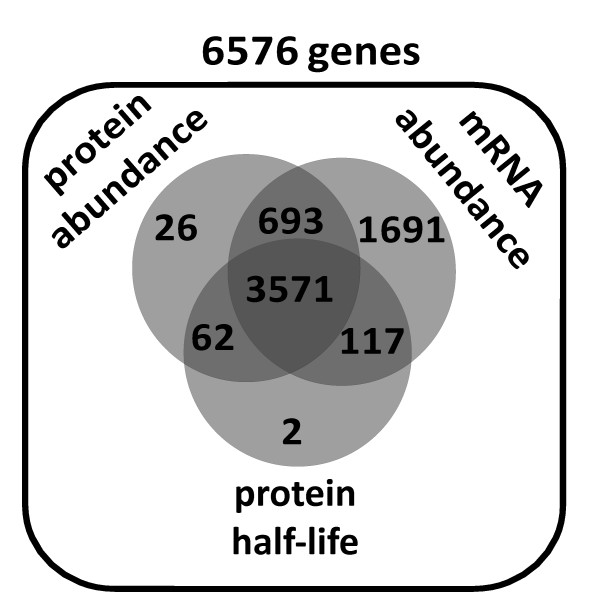
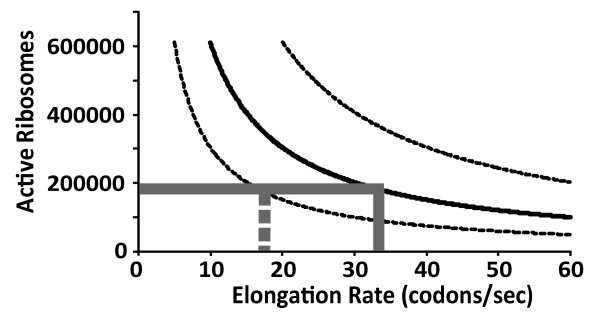
An examination of the accuracy of genome-wide expression datasets generated for Saccharomyces cerevisiae shows that the available datasets suffer from large random errors within studies as well as systematic shifts in reported values between studies, which make predictions of translational activity at the level of individual genes relatively inaccurate. In contrast, predictions of cell-wide translational activity are possible from such datasets with higher accuracy, and current datasets predict a production rate of about 13,000 proteins per haploid cell per second under fast growth conditions. This prediction is shown to be consistent with independently derived kinetic information on nucleotide exchange reactions that occur during translation, and on the ribosomal content of yeast cells.
This study highlights some of the limitations in published genome-wide expression datasets, but also demonstrates a novel use for such datasets in examining global properties of cells. The global translational activity of yeast cells predicted in this study is a useful benchmark against which biochemical data on individual translation factor activities can be interpreted.
信使mRNA的翻译对所有真核生物的基因表达调控起着重要作用。由于翻译控制通常涉及翻译活性的分数变化,因此需要对翻译活性进行良好的定量描述,以便全面理解生物学的这一方面。然而,在生理条件下通过实验很难生成关于翻译活性的数据,不过,作为一个参数,翻译活性原则上可通过已发表的全基因组数据集获得。
对酿酒酵母生成的全基因组表达数据集准确性的检查表明,现有数据集在研究内部存在较大随机误差,且不同研究报告的值存在系统偏差,这使得在单个基因水平上预测翻译活性相对不准确。相比之下,利用此类数据集可以更准确地预测全细胞的翻译活性,当前数据集预测在快速生长条件下,每个单倍体细胞每秒约产生13000种蛋白质。这一预测与独立得出的关于翻译过程中发生的核苷酸交换反应以及酵母细胞核糖体含量的动力学信息一致。
本研究突出了已发表的全基因组表达数据集的一些局限性,但也展示了此类数据集在研究细胞全局特性方面的新用途。本研究预测的酵母细胞全局翻译活性是一个有用的基准,可据此解释关于单个翻译因子活性的生化数据。