Letunic Ivica, Doerks Tobias, Bork Peer
EMBL, Meyerhofstrasse 1, 69012 Heidelberg, Germany.
Nucleic Acids Res. 2009 Jan;37(Database issue):D229-32. doi: 10.1093/nar/gkn808. Epub 2008 Oct 31.
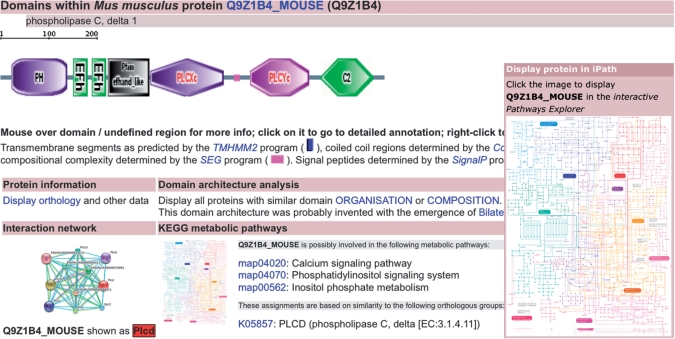
Simple modular architecture research tool (SMART) is an online tool (http://smart.embl.de/) for the identification and annotation of protein domains. It provides a user-friendly platform for the exploration and comparative study of domain architectures in both proteins and genes. The current release of SMART contains manually curated models for 784 protein domains. Recent developments were focused on further data integration and improving user friendliness. The underlying protein database based on completely sequenced genomes was greatly expanded and now includes 630 species, compared to 191 in the previous release. As an initial step towards integrating information on biological pathways into SMART, our domain annotations were extended with data on metabolic pathways and links to several pathways resources. The interaction network view was completely redesigned and is now available for more than 2 million proteins. In addition to the standard web access to the database, users can now query SMART using distributed annotation system (DAS) or through a simple object access protocol (SOAP) based web service.
简单模块化架构研究工具(SMART)是一个用于识别和注释蛋白质结构域的在线工具(http://smart.embl.de/)。它为蛋白质和基因中结构域架构的探索与比较研究提供了一个用户友好的平台。SMART的当前版本包含784个蛋白质结构域的人工整理模型。近期的发展集中在进一步的数据整合和提高用户友好性上。基于完全测序基因组的基础蛋白质数据库大幅扩展,目前包含630个物种,而上一版本为191个。作为将生物途径信息整合到SMART中的第一步,我们的结构域注释通过代谢途径数据以及与多个途径资源的链接得到了扩展。相互作用网络视图已完全重新设计,现在可用于超过200万种蛋白质。除了通过标准网页访问数据库外,用户现在还可以使用分布式注释系统(DAS)或通过基于简单对象访问协议(SOAP)的网络服务来查询SMART。