Congdon Peter
Department of Geography and Center for Statistics, Queen Mary University of London, London, UK.
Int J Health Geogr. 2009 Jan 30;8:6. doi: 10.1186/1476-072X-8-6.
Estimates of disease prevalence for small areas are increasingly required for the allocation of health funds according to local need. Both individual level and geographic risk factors are likely to be relevant to explaining prevalence variations, and in turn relevant to the procedure for small area prevalence estimation. Prevalence estimates are of particular importance for major chronic illnesses such as cardiovascular disease.
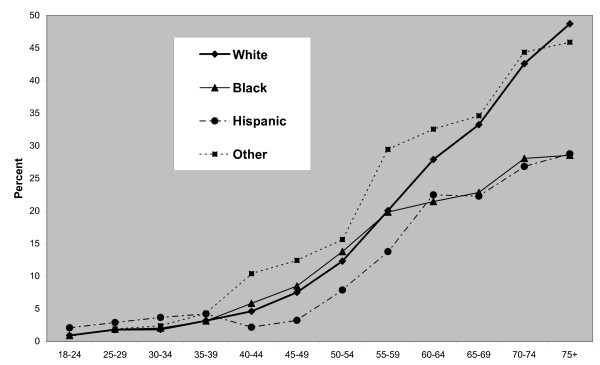
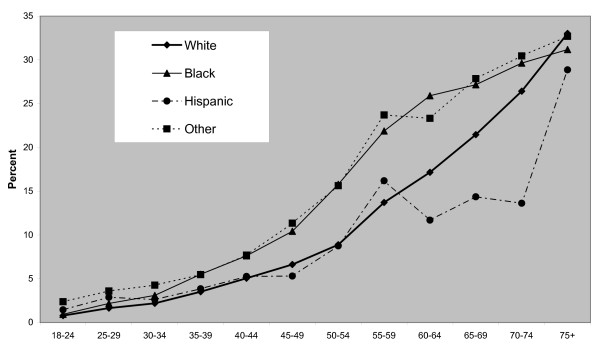
A multilevel prevalence model for cardiovascular outcomes is proposed that incorporates both survey information on patient risk factors and the effects of geographic location. The model is applied to derive micro area prevalence estimates, specifically estimates of cardiovascular disease for Zip Code Tabulation Areas in the USA. The model incorporates prevalence differentials by age, sex, ethnicity and educational attainment from the 2005 Behavioral Risk Factor Surveillance System survey. Influences of geographic context are modelled at both county and state level, with the county effects relating to poverty and urbanity. State level influences are modelled using a random effects approach that allows both for spatial correlation and spatial isolates.
To assess the importance of geographic variables, three types of model are compared: a model with person level variables only; a model with geographic effects that do not interact with person attributes; and a full model, allowing for state level random effects that differ by ethnicity. There is clear evidence that geographic effects improve statistical fit.
Geographic variations in disease prevalence partly reflect the demographic composition of area populations. However, prevalence variations may also show distinct geographic 'contextual' effects. The present study demonstrates by formal modelling methods that improved explanation is obtained by allowing for distinct geographic effects (for counties and states) and for interaction between geographic and person variables. Thus an appropriate methodology to estimate prevalence at small area level should include geographic effects as well as person level demographic variables.
根据当地需求分配卫生资金时,越来越需要对小区域的疾病患病率进行估计。个体层面和地理风险因素都可能与解释患病率差异相关,进而与小区域患病率估计程序相关。患病率估计对于心血管疾病等主要慢性病尤为重要。
提出了一种心血管疾病结局的多水平患病率模型,该模型纳入了患者风险因素的调查信息和地理位置的影响。该模型用于得出微观区域患病率估计值,特别是美国邮政编码分区的心血管疾病估计值。该模型纳入了2005年行为风险因素监测系统调查中按年龄、性别、种族和教育程度划分的患病率差异。在县和州层面模拟地理环境的影响,县层面的影响与贫困和城市化程度有关。州层面的影响采用随机效应方法进行模拟,该方法既考虑了空间相关性,也考虑了空间孤立性。
为评估地理变量的重要性,比较了三种类型的模型:仅有人口层面变量的模型;地理影响与人口属性不相互作用的模型;以及考虑按种族不同的州层面随机效应的完整模型。有明确证据表明地理影响改善了统计拟合度。
疾病患病率的地理差异部分反映了区域人口的人口构成。然而,患病率差异也可能显示出明显的地理“背景”效应。本研究通过形式化建模方法表明,通过考虑不同的地理影响(县和州层面)以及地理变量与人口变量之间的相互作用,可以获得更好的解释。因此,在小区域层面估计患病率的适当方法应包括地理影响以及人口层面的人口统计学变量。