Department of Epidemiology, School of Public Health, China Medical University, Shenyang 110001, PR China.
J Exp Clin Cancer Res. 2009 Jul 18;28(1):103. doi: 10.1186/1756-9966-28-103.
A reliable and precise classification is essential for successful diagnosis and treatment of cancer. Gene expression microarrays have provided the high-throughput platform to discover genomic biomarkers for cancer diagnosis and prognosis. Rational use of the available bioinformation can not only effectively remove or suppress noise in gene chips, but also avoid one-sided results of separate experiment. However, only some studies have been aware of the importance of prior information in cancer classification.
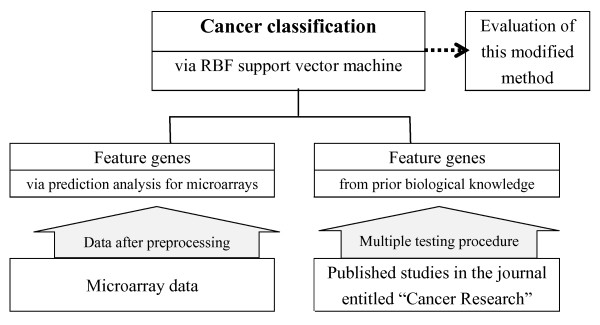
Together with the application of support vector machine as the discriminant approach, we proposed one modified method that incorporated prior knowledge into cancer classification based on gene expression data to improve accuracy. A public well-known dataset, Malignant pleural mesothelioma and lung adenocarcinoma gene expression database, was used in this study. Prior knowledge is viewed here as a means of directing the classifier using known lung adenocarcinoma related genes. The procedures were performed by software R 2.80.
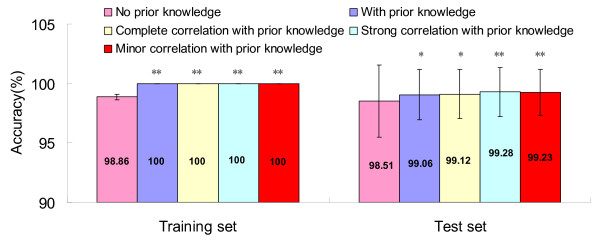
The modified method performed better after incorporating prior knowledge. Accuracy of the modified method improved from 98.86% to 100% in training set and from 98.51% to 99.06% in test set. The standard deviations of the modified method decreased from 0.26% to 0 in training set and from 3.04% to 2.10% in test set.
The method that incorporates prior knowledge into discriminant analysis could effectively improve the capacity and reduce the impact of noise. This idea may have good future not only in practice but also in methodology.
可靠和精确的分类对于癌症的成功诊断和治疗至关重要。基因表达微阵列为癌症诊断和预后的基因组生物标志物的发现提供了高通量平台。合理利用现有的生物信息不仅可以有效地去除或抑制基因芯片中的噪声,还可以避免单独实验的结果片面。然而,只有一些研究意识到了先验信息在癌症分类中的重要性。
我们提出了一种基于基因表达数据的改进方法,将先验知识纳入癌症分类中,以提高准确性。该方法结合支持向量机作为判别方法,共同使用。我们使用了一个公共的、众所周知的数据集,即恶性胸膜间皮瘤和肺腺癌基因表达数据库,来进行这项研究。在这里,先验知识被视为利用已知的肺腺癌相关基因指导分类器的一种手段。这些程序是通过软件 R 2.80 执行的。
在纳入先验知识后,改进的方法表现更好。改进方法在训练集的准确率从 98.86%提高到 100%,在测试集的准确率从 98.51%提高到 99.06%。改进方法在训练集的标准差从 0.26%降至 0,在测试集的标准差从 3.04%降至 2.10%。
将先验知识纳入判别分析的方法可以有效地提高能力并降低噪声的影响。这个想法不仅在实践中,而且在方法论上都有很好的前景。