California Institute for Telecommunications and Information Technology, University of California San Diego, La Jolla, CA, USA.
Bioinformatics. 2010 Mar 1;26(5):680-2. doi: 10.1093/bioinformatics/btq003. Epub 2010 Jan 6.
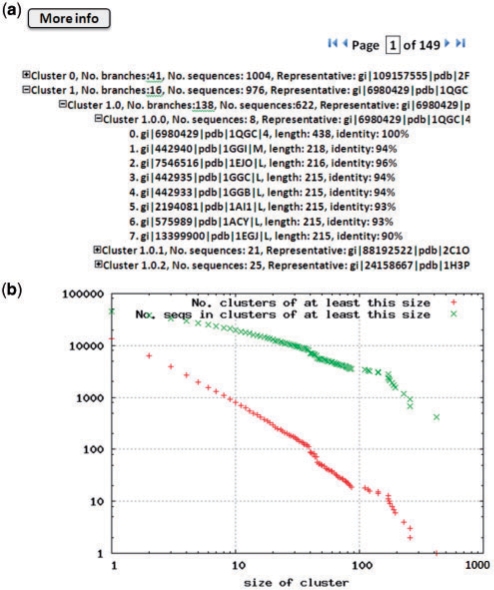
CD-HIT is a widely used program for clustering and comparing large biological sequence datasets. In order to further assist the CD-HIT users, we significantly improved this program with more functions and better accuracy, scalability and flexibility. Most importantly, we developed a new web server, CD-HIT Suite, for clustering a user-uploaded sequence dataset or comparing it to another dataset at different identity levels. Users can now interactively explore the clusters within web browsers. We also provide downloadable clusters for several public databases (NCBI NR, Swissprot and PDB) at different identity levels.
Free access at http://cd-hit.org
CD-HIT 是一个广泛使用的程序,用于聚类和比较大型生物序列数据集。为了进一步帮助 CD-HIT 用户,我们对该程序进行了重大改进,增加了更多功能,提高了准确性、可扩展性和灵活性。最重要的是,我们开发了一个新的 Web 服务器 CD-HIT Suite,用于对用户上传的序列数据集进行聚类,或在不同的同一性水平上与另一个数据集进行比较。用户现在可以在网络浏览器中交互式地探索聚类。我们还提供了在不同同一性水平下的几个公共数据库(NCBI NR、Swissprot 和 PDB)的可下载聚类。
免费访问网址:http://cd-hit.org