Bioinformatics Group, Department of Electrical Engineering, Katholieke Universiteit Leuven, Kasteelpark Arenberg 10, Heverlee B3001, Belgium.
BMC Bioinformatics. 2010 Jan 14;11:28. doi: 10.1186/1471-2105-11-28.
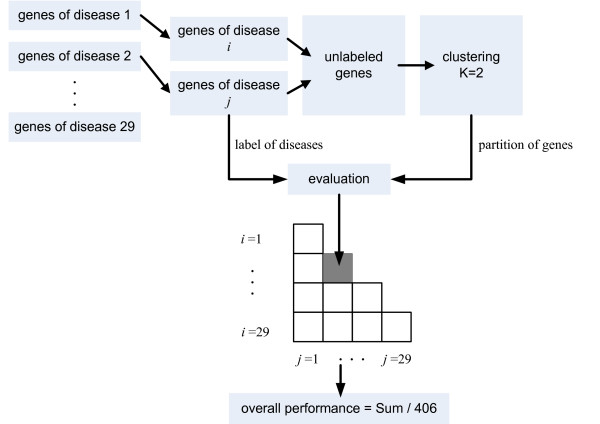
Text mining has become a useful tool for biologists trying to understand the genetics of diseases. In particular, it can help identify the most interesting candidate genes for a disease for further experimental analysis. Many text mining approaches have been introduced, but the effect of disease-gene identification varies in different text mining models. Thus, the idea of incorporating more text mining models may be beneficial to obtain more refined and accurate knowledge. However, how to effectively combine these models still remains a challenging question in machine learning. In particular, it is a non-trivial issue to guarantee that the integrated model performs better than the best individual model.
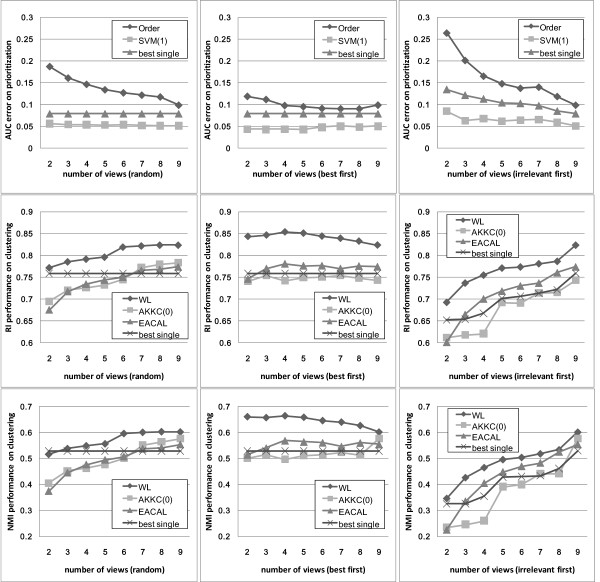
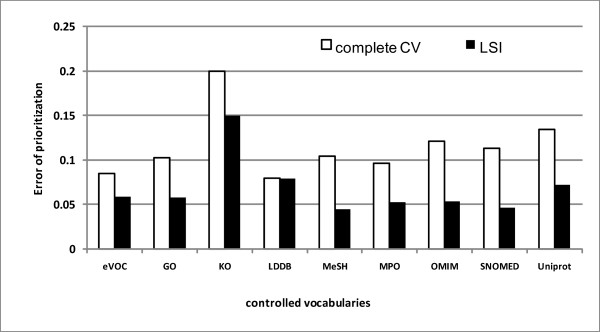
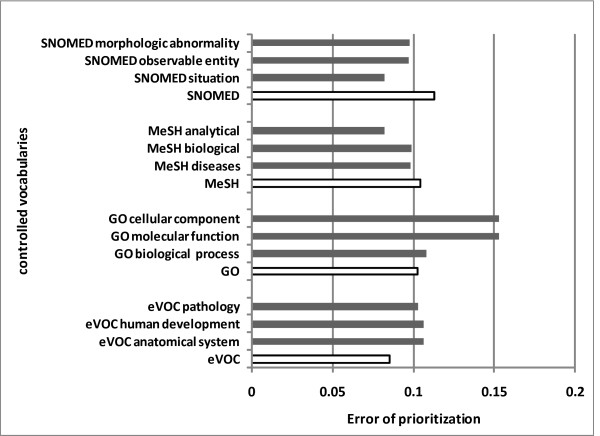
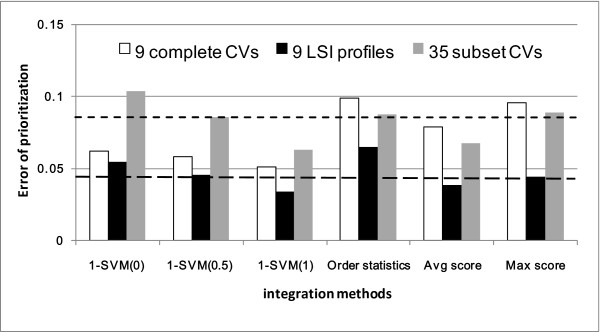
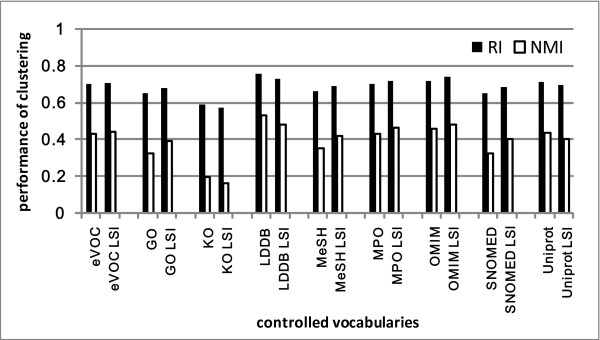
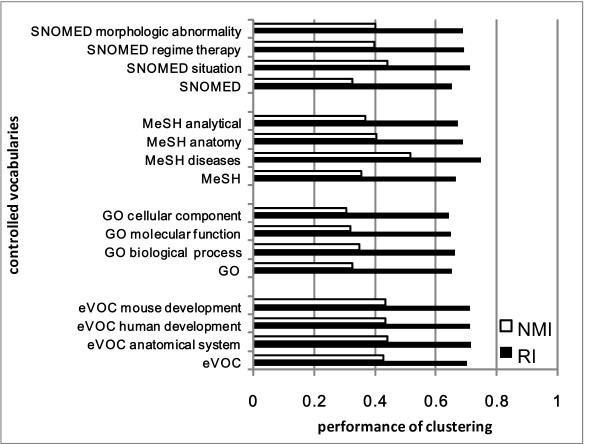
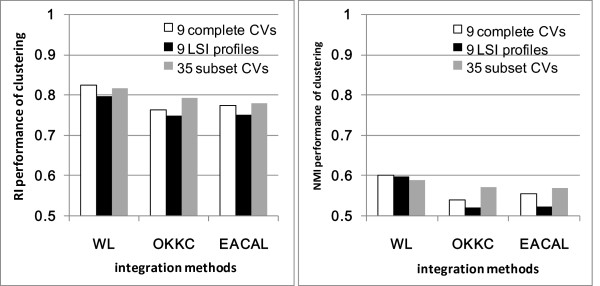
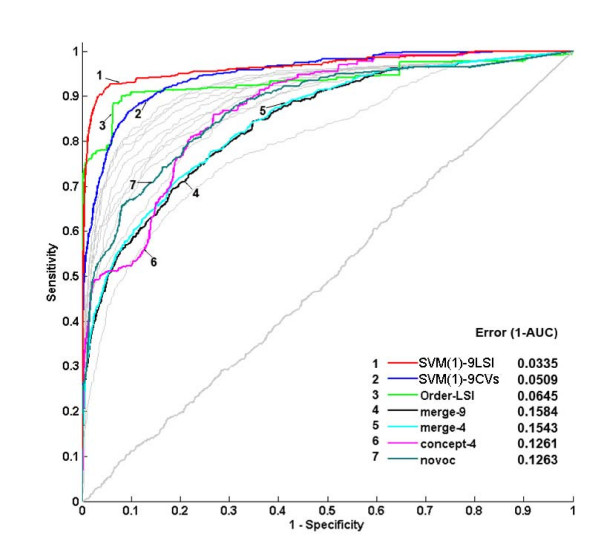
We present a multi-view approach to retrieve biomedical knowledge using different controlled vocabularies. These controlled vocabularies are selected on the basis of nine well-known bio-ontologies and are applied to index the vast amounts of gene-based free-text information available in the MEDLINE repository. The text mining result specified by a vocabulary is considered as a view and the obtained multiple views are integrated by multi-source learning algorithms. We investigate the effect of integration in two fundamental computational disease gene identification tasks: gene prioritization and gene clustering. The performance of the proposed approach is systematically evaluated and compared on real benchmark data sets. In both tasks, the multi-view approach demonstrates significantly better performance than other comparing methods.
In practical research, the relevance of specific vocabulary pertaining to the task is usually unknown. In such case, multi-view text mining is a superior and promising strategy for text-based disease gene identification.
文本挖掘已成为生物学家试图理解疾病遗传学的有用工具。特别是,它可以帮助识别疾病最有趣的候选基因,以便进一步进行实验分析。已经引入了许多文本挖掘方法,但是不同文本挖掘模型中的疾病-基因识别效果有所不同。因此,引入更多文本挖掘模型的想法可能有助于获得更精细和准确的知识。但是,如何有效地结合这些模型仍然是机器学习中的一个具有挑战性的问题。特别是,保证集成模型的性能优于最佳的单个模型是一个非平凡的问题。
我们提出了一种多视图方法,使用不同的受控词汇表来检索生物医学知识。这些受控词汇表是基于九个著名的生物本体选择的,并应用于对 MEDLINE 存储库中大量基于基因的自由文本信息进行索引。词汇表指定的文本挖掘结果被视为一个视图,并且通过多源学习算法集成获得的多个视图。我们在两个基本的计算性疾病基因识别任务(基因优先级和基因聚类)中研究了集成的效果。在这两个任务中,多视图方法的性能均明显优于其他比较方法。
在实际研究中,与任务相关的特定词汇的相关性通常是未知的。在这种情况下,多视图文本挖掘是一种用于基于文本的疾病基因识别的优越且有前途的策略。