Department of Computer Science, UCI, Irvine, CA 92697-3435, USA.
Neural Netw. 2010 Jun;23(5):649-66. doi: 10.1016/j.neunet.2009.12.007. Epub 2009 Dec 28.
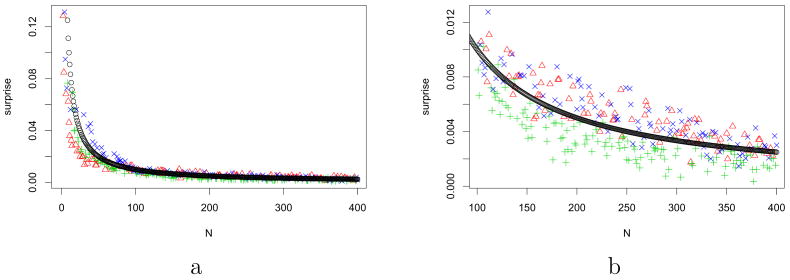
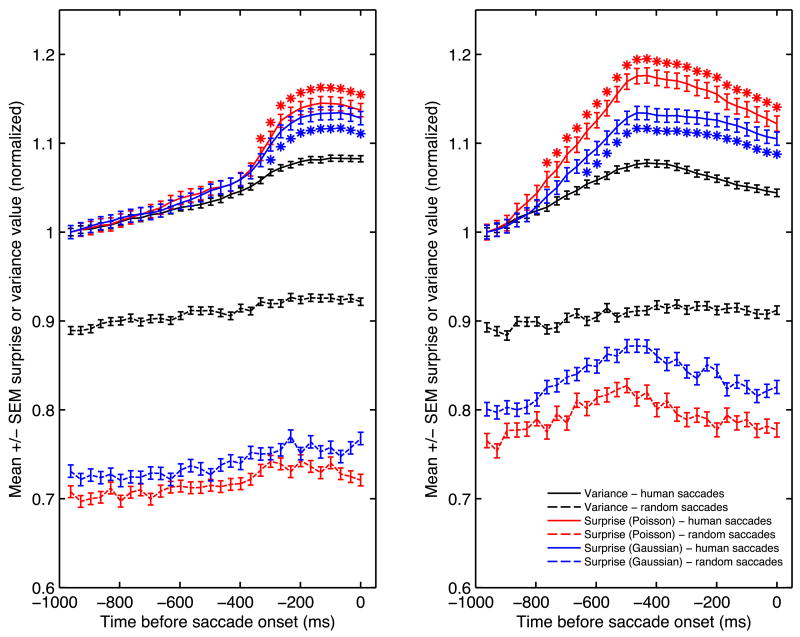
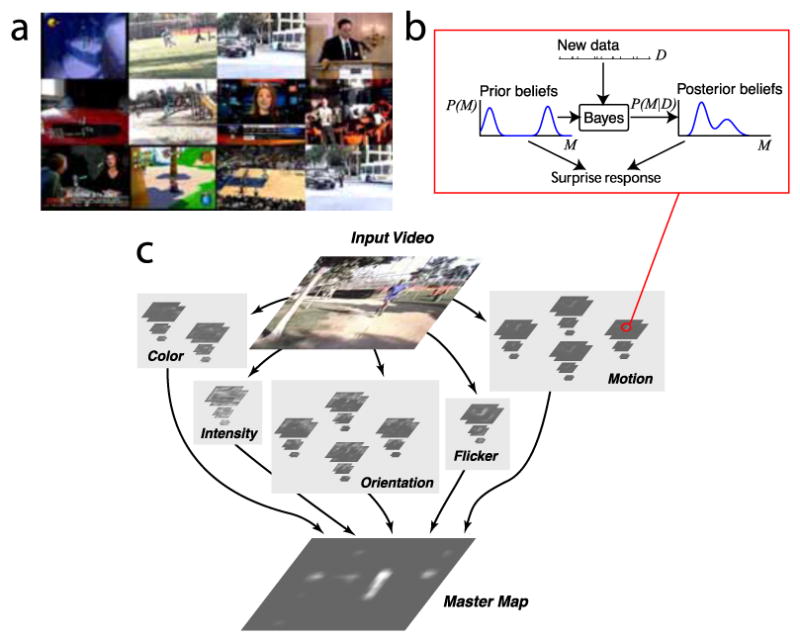
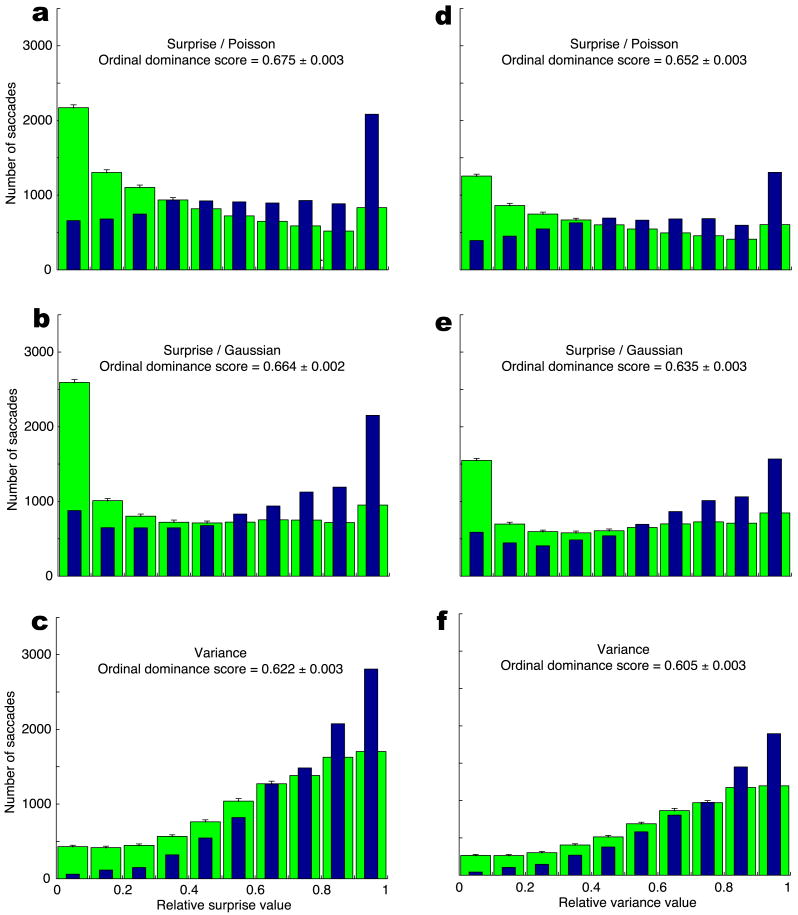
The amount of information contained in a piece of data can be measured by the effect this data has on its observer. Fundamentally, this effect is to transform the observer's prior beliefs into posterior beliefs, according to Bayes theorem. Thus the amount of information can be measured in a natural way by the distance (relative entropy) between the prior and posterior distributions of the observer over the available space of hypotheses. This facet of information, termed "surprise", is important in dynamic situations where beliefs change, in particular during learning and adaptation. Surprise can often be computed analytically, for instance in the case of distributions from the exponential family, or it can be numerically approximated. During sequential Bayesian learning, surprise decreases as the inverse of the number of training examples. Theoretical properties of surprise are discussed, in particular how it differs and complements Shannon's definition of information. A computer vision neural network architecture is then presented capable of computing surprise over images and video stimuli. Hypothesizing that surprising data ought to attract natural or artificial attention systems, the output of this architecture is used in a psychophysical experiment to analyze human eye movements in the presence of natural video stimuli. Surprise is found to yield robust performance at predicting human gaze (ROC-like ordinal dominance score approximately 0.7 compared to approximately 0.8 for human inter-observer repeatability, approximately 0.6 for simpler intensity contrast-based predictor, and 0.5 for chance). The resulting theory of surprise is applicable across different spatio-temporal scales, modalities, and levels of abstraction.
数据中所包含的信息量可以通过该数据对其观测者产生的影响来衡量。从根本上说,根据贝叶斯定理,这种影响是将观测者的先验信念转化为后验信念。因此,信息量可以通过观测者在假设可用空间中的先验和后验分布之间的距离(相对熵)以自然的方式进行测量。信息的这一方面,称为“惊喜”,在信念发生变化的动态情况下很重要,特别是在学习和适应期间。惊喜通常可以通过分析计算得出,例如在指数族分布的情况下,或者可以通过数值近似计算。在顺序贝叶斯学习期间,惊喜随着训练样本数量的倒数而减少。讨论了惊喜的理论性质,特别是它如何与香农的信息定义不同并补充了香农的信息定义。然后提出了一种能够计算图像和视频刺激上惊喜的计算机视觉神经网络架构。假设令人惊讶的数据应该吸引自然或人为的注意系统,该架构的输出被用于心理物理实验中,以分析在自然视频刺激存在下的人类眼球运动。惊喜在预测人类注视方面表现出稳健的性能(ROC 样有序优势得分约为 0.7,而人类观察者之间的可重复性约为 0.8,基于更简单的强度对比度的预测器约为 0.6,而机会约为 0.5)。由此产生的惊喜理论适用于不同的时空尺度、模态和抽象级别。