Department of Computer Science, Sichuan University, Chengdu, Sichuan, PR China.
BMC Bioinformatics. 2010 Jan 20;11:40. doi: 10.1186/1471-2105-11-40.
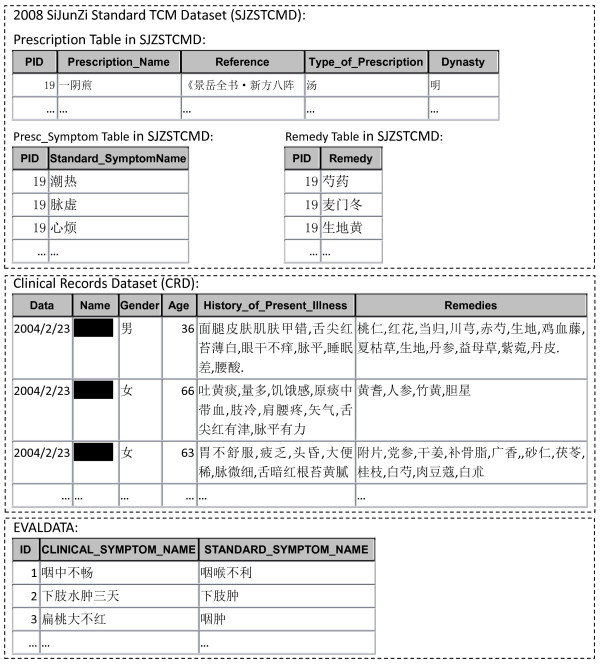
In recent years, Data Mining technology has been applied more than ever before in the field of traditional Chinese medicine (TCM) to discover regularities from the experience accumulated in the past thousands of years in China. Electronic medical records (or clinical records) of TCM, containing larger amount of information than well-structured data of prescriptions extracted manually from TCM literature such as information related to medical treatment process, could be an important source for discovering valuable regularities of TCM. However, they are collected by TCM doctors on a day to day basis without the support of authoritative editorial board, and owing to different experience and background of TCM doctors, the same concept might be described in several different terms. Therefore, clinical records of TCM cannot be used directly to Data Mining and Knowledge Discovery. This paper focuses its attention on the phenomena of "one symptom with different names" and investigates a series of metrics for automatically normalizing symptom names in clinical records of TCM.
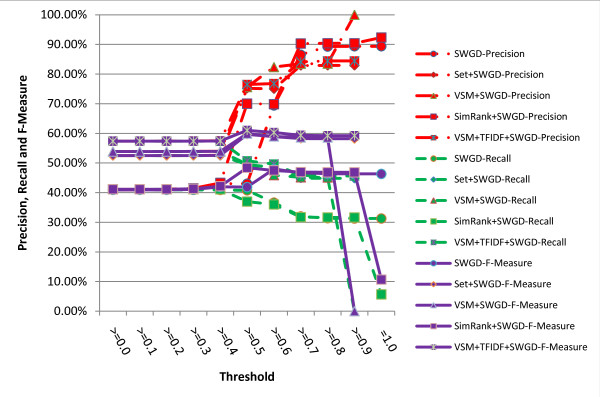
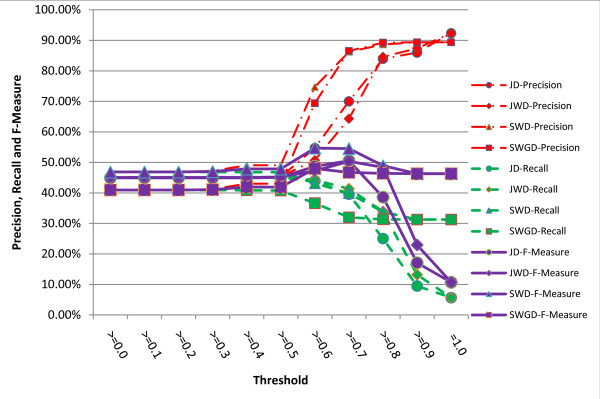
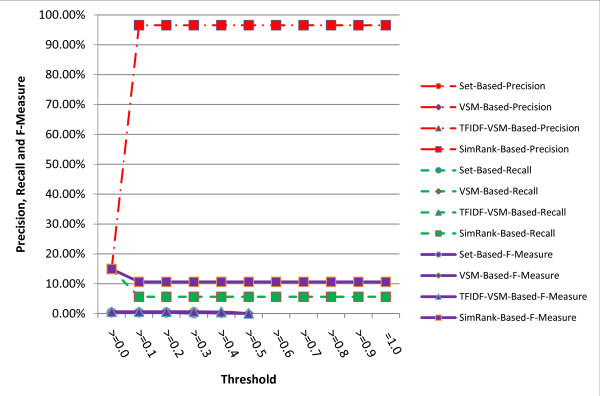
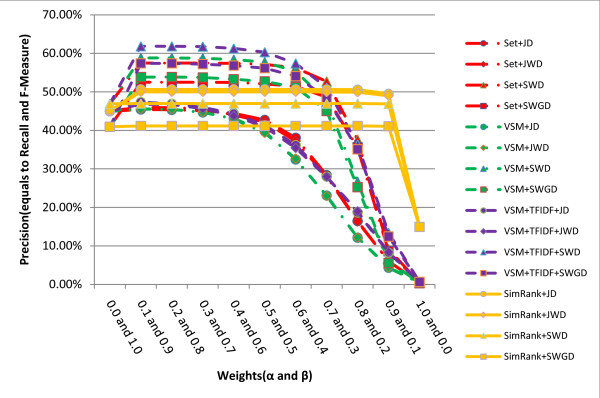
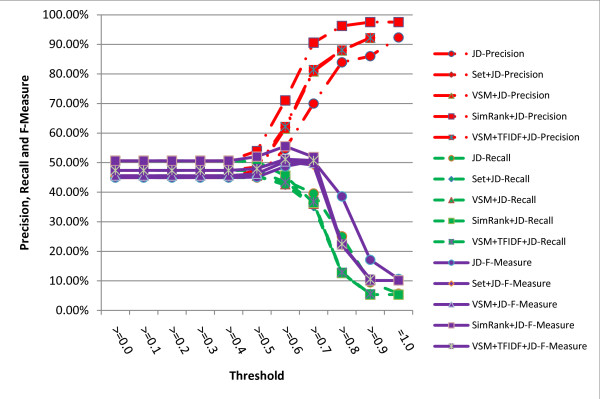
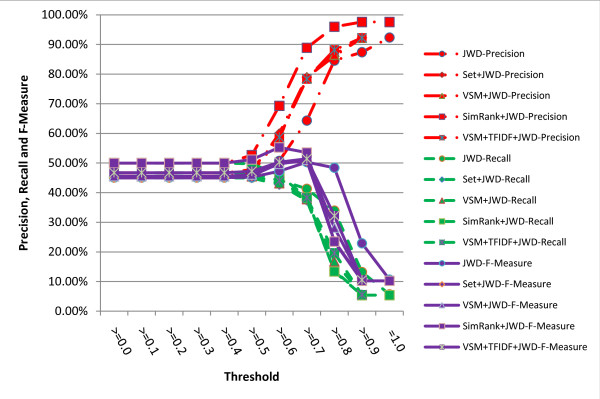
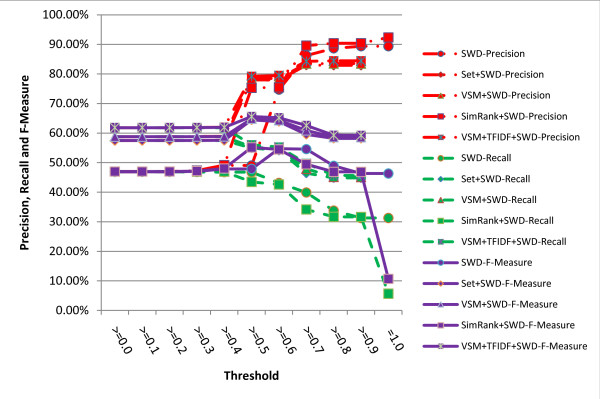
A series of extensive experiments were performed to validate the metrics proposed, and they have shown that the hybrid similarity metrics integrating literal similarity and remedy-based similarity are more accurate than the others which are based on literal similarity or remedy-based similarity alone, and the highest F-Measure (65.62%) of all the metrics is achieved by hybrid similarity metric VSM+TFIDF+SWD.
Automatic symptom name normalization is an essential task for discovering knowledge from clinical data of TCM. The problem is introduced for the first time by this paper. The results have verified that the investigated metrics are reasonable and accurate, and the hybrid similarity metrics are much better than the metrics based on literal similarity or remedy-based similarity alone.
近年来,数据挖掘技术在中医领域的应用比以往任何时候都更加广泛,旨在从中国过去几千年积累的经验中发现规律。中医的电子病历(或临床记录)包含的信息量比从中医文献中手动提取的处方等结构化数据多,可能是发现中医有价值规律的重要来源。然而,它们是由中医医生在日常工作中收集的,没有得到权威编辑委员会的支持,由于中医医生的经验和背景不同,同一个概念可能会用几个不同的术语来描述。因此,中医的临床记录不能直接用于数据挖掘和知识发现。本文关注“一症多名”现象,并研究了一系列自动规范中医临床记录中症状名称的指标。
进行了一系列广泛的实验来验证所提出的指标,结果表明,整合字面相似性和基于治疗相似性的混合相似性指标比仅基于字面相似性或基于治疗相似性的指标更准确,所有指标中最高的 F 度量(65.62%)是由混合相似性指标 VSM+TFIDF+SWD 实现的。
自动症状名称规范化是从中医临床数据中发现知识的必要任务。本文首次提出了这个问题。结果验证了所研究的指标是合理和准确的,混合相似性指标明显优于仅基于字面相似性或基于治疗相似性的指标。