Second Affiliated Hospital Zhejiang University School of Medicine, Hangzhou, Zhejiang Province 310000, China.
Sir Run Run Shaw Hospital Zhejiang University School of Medicine, Hangzhou, Zhejiang Province 310000, China.
J Healthc Eng. 2017;2017:4898963. doi: 10.1155/2017/4898963. Epub 2017 Jul 5.
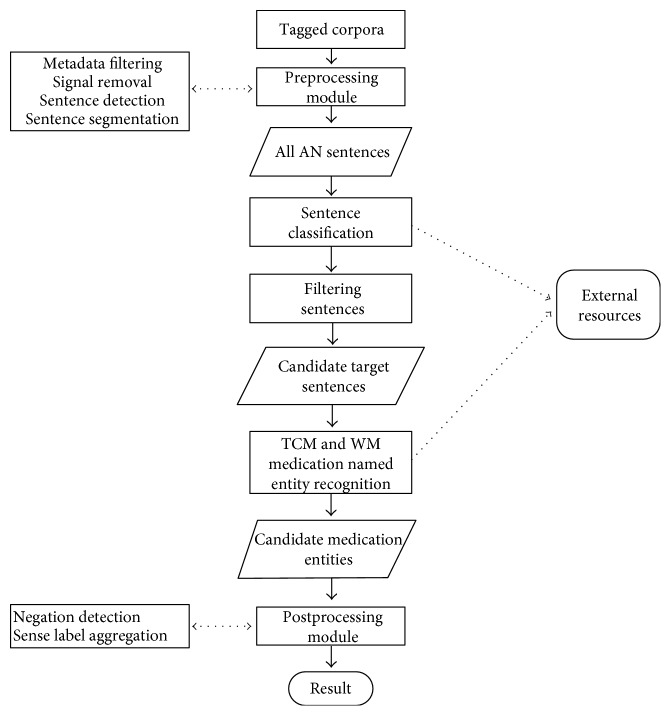
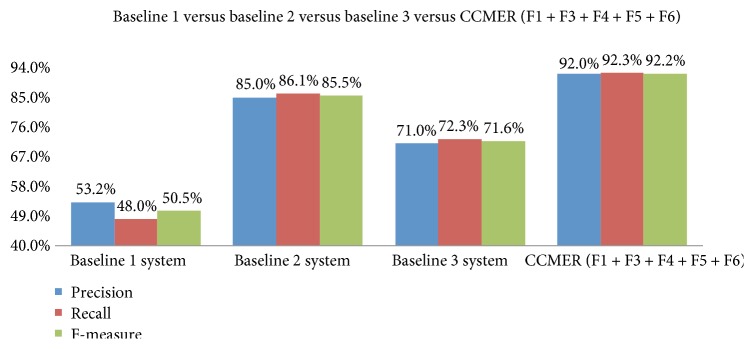
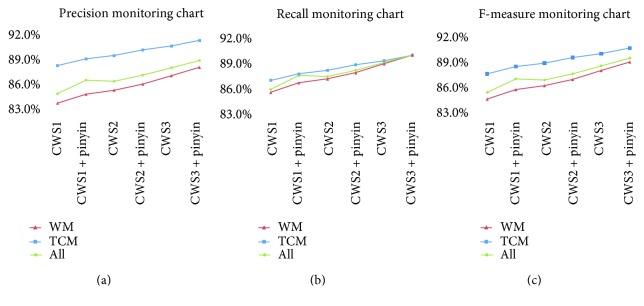
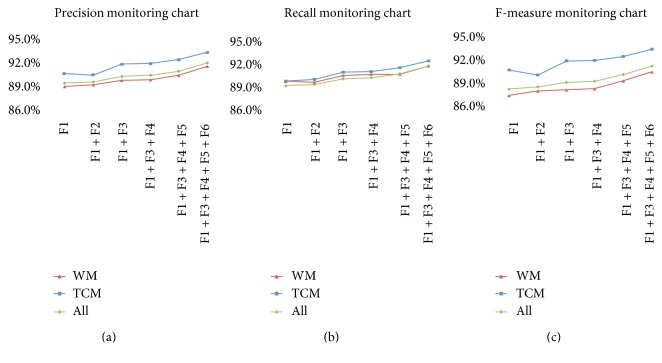
Medical entity recognition, a basic task in the language processing of clinical data, has been extensively studied in analyzing admission notes in alphabetic languages such as English. However, much less work has been done on nonstructural texts that are written in Chinese, or in the setting of differentiation of Chinese drug names between traditional Chinese medicine and Western medicine. Here, we propose a novel cascade-type Chinese medication entity recognition approach that aims at integrating the sentence category classifier from a support vector machine and the conditional random field-based medication entity recognition. We hypothesized that this approach could avoid the side effects of abundant negative samples and improve the performance of the named entity recognition from admission notes written in Chinese. Therefore, we applied this approach to a test set of 324 Chinese-written admission notes with manual annotation by medical experts. Our data demonstrated that this approach had a score of 94.2% in precision, 92.8% in recall, and 93.5% in F-measure for the recognition of traditional Chinese medicine drug names and 91.2% in precision, 92.6% in recall, and 91.7% F-measure for the recognition of Western medicine drug names. The differences in F-measure were significant compared with those in the baseline systems.
医学实体识别是临床数据语言处理中的一个基本任务,在分析英语等字母语言的入院记录时已经得到了广泛研究。然而,对于用中文书写的非结构化文本,或者在区分中药和西药药物名称方面的研究工作要少得多。在这里,我们提出了一种新的级联式中药药物实体识别方法,旨在整合来自支持向量机的句子类别分类器和基于条件随机场的药物实体识别。我们假设这种方法可以避免大量负样本的副作用,并提高中文入院记录中命名实体识别的性能。因此,我们将这种方法应用于一组由医学专家手动注释的 324 份中文入院记录的测试集。我们的数据表明,这种方法在识别中药药物名称时的精度、召回率和 F1 分数分别为 94.2%、92.8%和 93.5%,在识别西药药物名称时的精度、召回率和 F1 分数分别为 91.2%、92.6%和 91.7%。与基线系统相比,F1 分数的差异具有统计学意义。