Vaughan Laura K, Divers Jasmin, Padilla Miguel, Redden David T, Tiwari Hemant K, Pomp Daniel, Allison David B
Department of Biostatistics, Section on Statistical Genetics, University of Alabama at Birmingham, Birmingham, Alabama 35294.
Comput Stat Data Anal. 2009 Mar 15;53(5):1755-1766. doi: 10.1016/j.csda.2008.02.032.
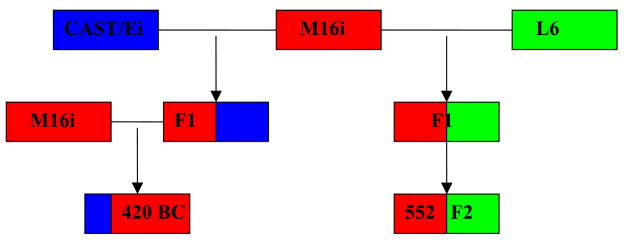
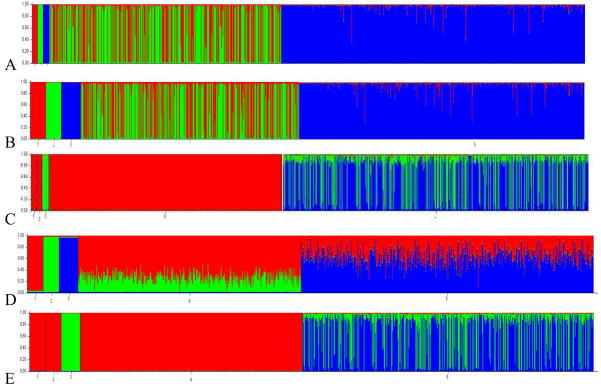
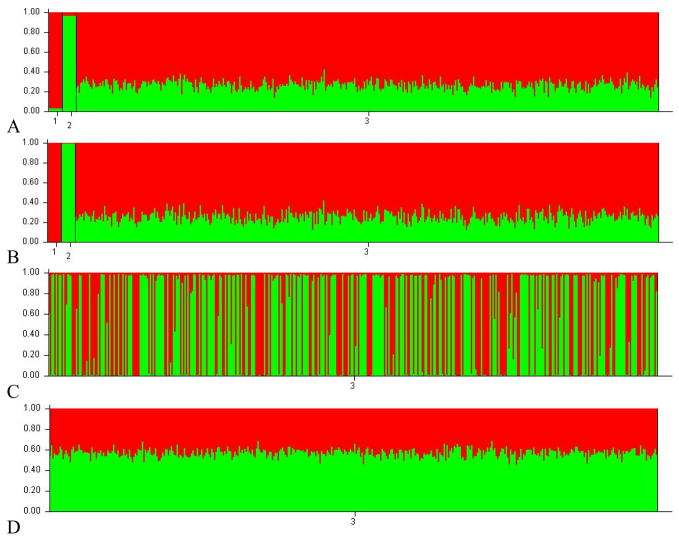
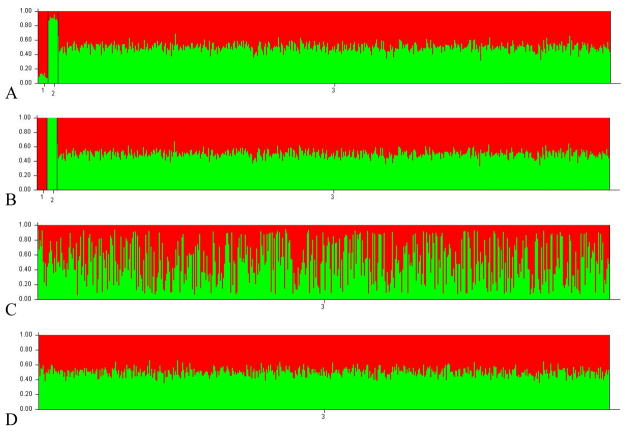
With the advent of powerful computers, simulation studies are becoming an important tool in statistical methodology research. However, computer simulations of a specific process are only as good as our understanding of the underlying mechanisms. An attractive supplement to simulations is the use of plasmode datasets. Plasmodes are data sets that are generated by natural biologic processes, under experimental conditions that allow some aspect of the truth to be known. The benefit of the plasmode approach is that the data are generated through completely natural processes, thus circumventing the common concern of the realism and accuracy of computer simulated data. The estimation of admixture, or the proportion of an individual's genome that originates from different founding populations, is a particularly difficult research endeavor that is well suited to the use of plasmodes. Current methods have been tested with simulations of complex populations where the underlying mechanisms such as the rate and distribution of recombination are not well understood. To demonstrate the utility of this method data derived from mouse crosses is used to evaluate the effectiveness of several admixture estimation methodologies. Each cross shares a common founding population so that the ancestry proportion for each individual is known, allowing for the comparison of true and estimated individual admixture values. Analysis shows that the different estimation methodologies (Structure, AdmixMap and FRAPPE) examined all perform well with simple datasets. However, the performance of the estimation methodologies varied greatly when applied to a plasmode consisting of three founding populations. The results of these examples illustrate the utility of plasmodes in the evaluation of statistical genetics methodologies.
随着功能强大的计算机的出现,模拟研究正成为统计方法研究中的一种重要工具。然而,特定过程的计算机模拟效果仅取决于我们对潜在机制的理解程度。模拟的一个有吸引力的补充是使用模式数据集。模式数据集是在允许了解部分真相的实验条件下由自然生物过程生成的数据集。模式方法的好处在于数据是通过完全自然的过程生成的,从而避免了对计算机模拟数据的真实性和准确性的常见担忧。混合比例的估计,即个体基因组中源自不同创始群体的比例,是一项特别困难的研究工作,非常适合使用模式数据集。目前的方法已经在复杂群体的模拟中进行了测试,而这些群体的潜在机制,如重组率和分布,尚未得到很好的理解。为了证明这种方法的实用性,来自小鼠杂交的数据被用于评估几种混合比例估计方法的有效性。每个杂交都有一个共同的创始群体,因此每个个体的祖先比例是已知的,这使得可以比较真实和估计的个体混合值。分析表明,所研究的不同估计方法(Structure、AdmixMap和FRAPPE)在简单数据集上都表现良好。然而,当应用于由三个创始群体组成的模式数据集时,估计方法的性能差异很大。这些例子的结果说明了模式数据集在评估统计遗传学方法中的实用性。