Molecular Structure and Function Program, Hospital for Sick Children, Department of Molecular Genetics, University of Toronto, Toronto, ON, Canada.
Nucleic Acids Res. 2010 Dec;38(22):7927-42. doi: 10.1093/nar/gkq714. Epub 2010 Aug 12.
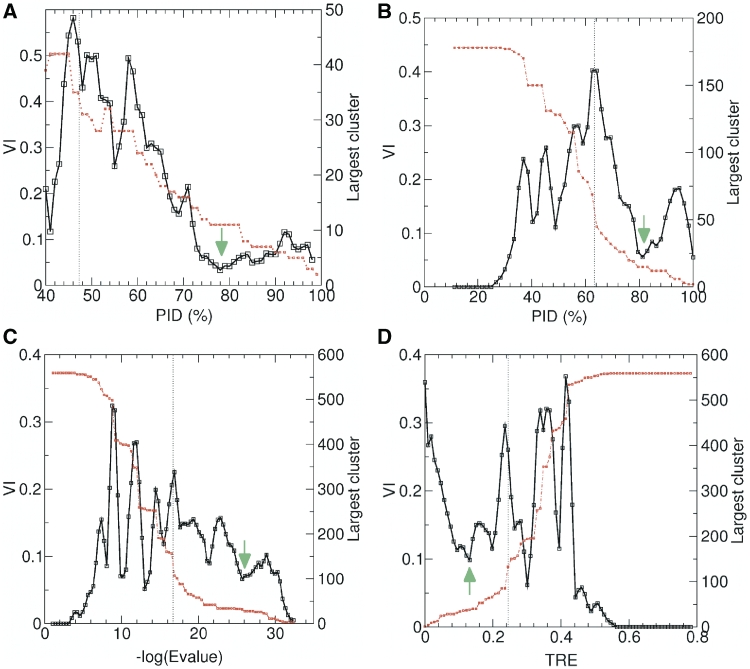
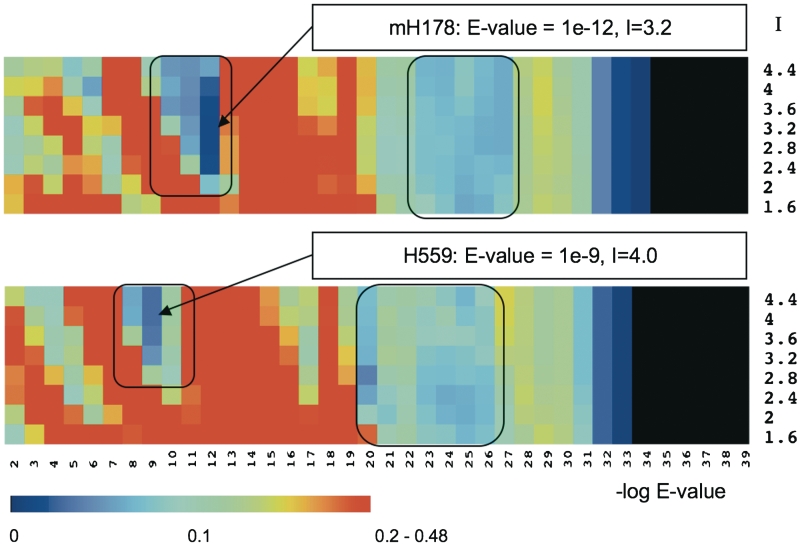
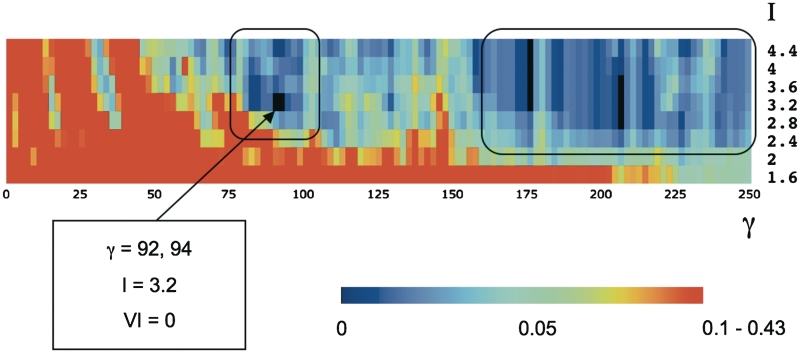
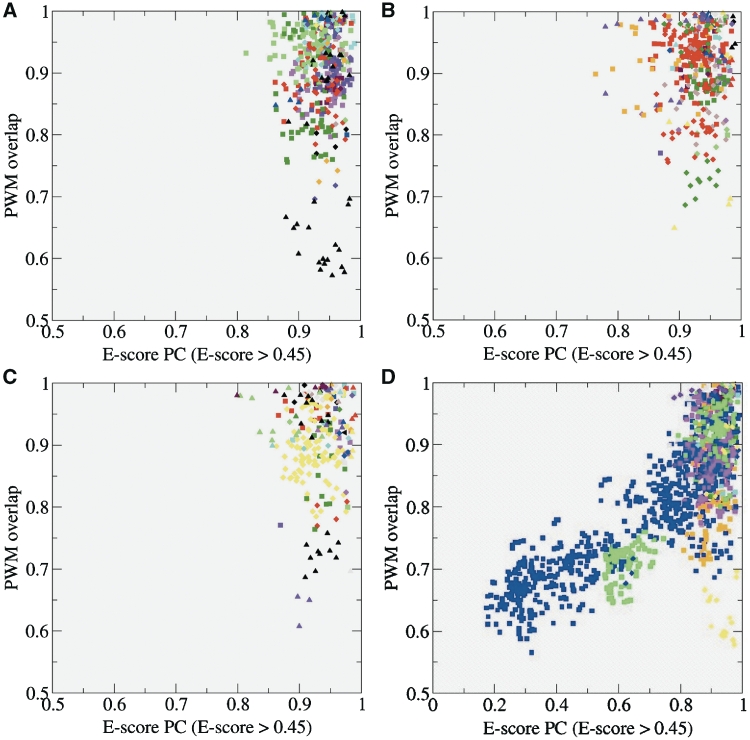
Classifying proteins into subgroups with similar molecular function on the basis of sequence is an important step in deriving reliable functional annotations computationally. So far, however, available classification procedures have been evaluated against protein subgroups that are defined by experts using mainly qualitative descriptions of molecular function. Recently, in vitro DNA-binding preferences to all possible 8-nt DNA sequences have been measured for 178 mouse homeodomains using protein-binding microarrays, offering the unprecedented opportunity of evaluating the classification methods against quantitative measures of molecular function. To this end, we automatically derive homeodomain subtypes from the DNA-binding data and independently group the same domains using sequence information alone. We test five sequence-based methods, which use different sequence-similarity measures and algorithms to group sequences. Results show that methods that optimize the classification robustness reflect well the detailed functional specificity revealed by the experimental data. In some of these classifications, 73-83% of the subfamilies exactly correspond to, or are completely contained in, the function-based subtypes. Our findings demonstrate that certain sequence-based classifications are capable of yielding very specific molecular function annotations. The availability of quantitative descriptions of molecular function, such as DNA-binding data, will be a key factor in exploiting this potential in the future.
将蛋白质按其分子功能相似性分类到亚组中,是从计算上推导出可靠功能注释的重要步骤。然而,到目前为止,可用的分类程序是针对专家使用主要基于分子功能的定性描述来定义的蛋白质亚组进行评估的。最近,使用蛋白质结合微阵列测量了 178 个小鼠同源域对所有可能的 8 个核苷酸 DNA 序列的体外 DNA 结合偏好性,为评估分类方法对分子功能的定量测量提供了前所未有的机会。为此,我们从 DNA 结合数据中自动推导出同源域亚型,并仅使用序列信息独立地对同一结构域进行分组。我们测试了五种基于序列的方法,这些方法使用不同的序列相似性度量和算法来对序列进行分组。结果表明,优化分类稳健性的方法很好地反映了实验数据揭示的详细功能特异性。在这些分类中的某些分类中,73%-83%的亚科与基于功能的亚型完全对应或完全包含在其中。我们的发现表明,某些基于序列的分类能够产生非常具体的分子功能注释。将来,定量描述分子功能(如 DNA 结合数据)的可用性将是利用这一潜力的关键因素。