Bergen Center for Computational Science, Uni Research, Bergen, Norway.
Bioinformatics. 2010 Sep 15;26(18):i540-6. doi: 10.1093/bioinformatics/btq391.
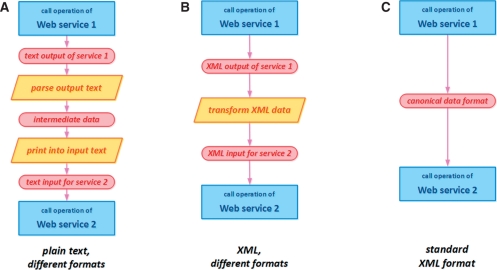
The world-wide community of life scientists has access to a large number of public bioinformatics databases and tools, which are developed and deployed using diverse technologies and designs. More and more of the resources offer programmatic web-service interface. However, efficient use of the resources is hampered by the lack of widely used, standard data-exchange formats for the basic, everyday bioinformatics data types.
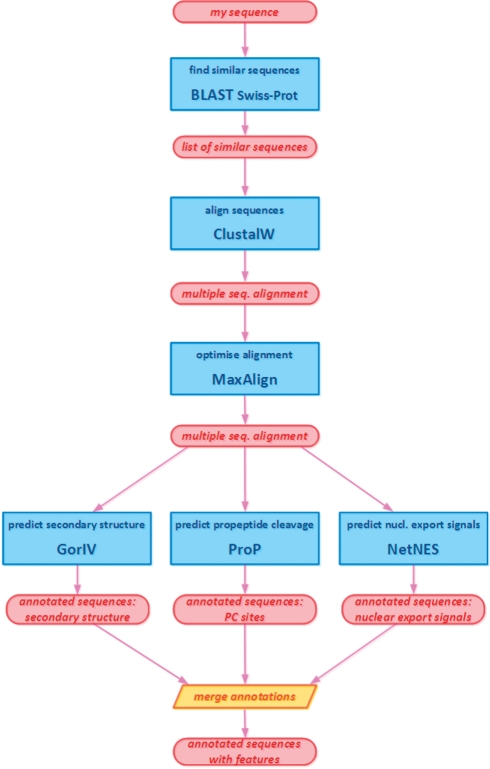
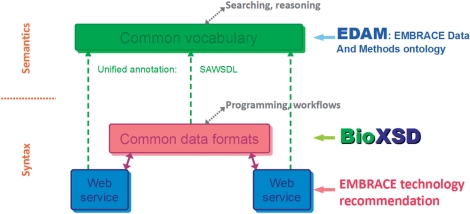
BioXSD has been developed as a candidate for standard, canonical exchange format for basic bioinformatics data. BioXSD is represented by a dedicated XML Schema and defines syntax for biological sequences, sequence annotations, alignments and references to resources. We have adapted a set of web services to use BioXSD as the input and output format, and implemented a test-case workflow. This demonstrates that the approach is feasible and provides smooth interoperability. Semantics for BioXSD is provided by annotation with the EDAM ontology. We discuss in a separate section how BioXSD relates to other initiatives and approaches, including existing standards and the Semantic Web.
The BioXSD 1.0 XML Schema is freely available at http://www.bioxsd.org/BioXSD-1.0.xsd under the Creative Commons BY-ND 3.0 license. The http://bioxsd.org web page offers documentation, examples of data in BioXSD format, example workflows with source codes in common programming languages, an updated list of compatible web services and tools and a repository of feature requests from the community.
全球生命科学领域的研究人员可以访问大量公共生物信息学数据库和工具,这些数据库和工具是使用不同的技术和设计开发和部署的。越来越多的资源提供了可编程的 Web 服务接口。然而,由于缺乏广泛使用的、标准的数据交换格式来表示基本的日常生物信息学数据类型,因此这些资源的高效利用受到了阻碍。
BioXSD 已被开发为基本生物信息学数据的标准、规范交换格式的候选者。BioXSD 由专门的 XML 模式表示,并定义了生物序列、序列注释、比对和资源引用的语法。我们已经对一组 Web 服务进行了适配,使其可以使用 BioXSD 作为输入和输出格式,并实现了一个测试用例工作流程。这证明了该方法是可行的,并提供了顺畅的互操作性。BioXSD 的语义由 EDAM 本体进行注释。我们在单独的一节中讨论了 BioXSD 与其他倡议和方法的关系,包括现有标准和语义 Web。
BioXSD 1.0 XML 模式可在 Creative Commons BY-ND 3.0 许可证下免费从 http://www.bioxsd.org/BioXSD-1.0.xsd 获取。http://bioxsd.org 网页提供了文档、BioXSD 格式的数据示例、带有常见编程语言源代码的示例工作流程、兼容的 Web 服务和工具的更新列表以及来自社区的功能请求存储库。