Department of Electrical Engineering (ESAT-SCD) Katholieke Universiteit Leuven, 3001 Leuven, Belgium.
BMC Bioinformatics. 2010 Sep 14;11:460. doi: 10.1186/1471-2105-11-460.
Discovering novel disease genes is still challenging for diseases for which no prior knowledge--such as known disease genes or disease-related pathways--is available. Performing genetic studies frequently results in large lists of candidate genes of which only few can be followed up for further investigation. We have recently developed a computational method for constitutional genetic disorders that identifies the most promising candidate genes by replacing prior knowledge by experimental data of differential gene expression between affected and healthy individuals.To improve the performance of our prioritization strategy, we have extended our previous work by applying different machine learning approaches that identify promising candidate genes by determining whether a gene is surrounded by highly differentially expressed genes in a functional association or protein-protein interaction network.
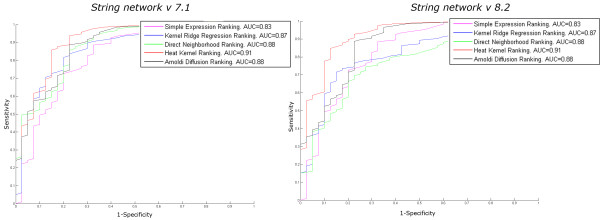
We have proposed three strategies scoring disease candidate genes relying on network-based machine learning approaches, such as kernel ridge regression, heat kernel, and Arnoldi kernel approximation. For comparison purposes, a local measure based on the expression of the direct neighbors is also computed. We have benchmarked these strategies on 40 publicly available knockout experiments in mice, and performance was assessed against results obtained using a standard procedure in genetics that ranks candidate genes based solely on their differential expression levels (Simple Expression Ranking). Our results showed that our four strategies could outperform this standard procedure and that the best results were obtained using the Heat Kernel Diffusion Ranking leading to an average ranking position of 8 out of 100 genes, an AUC value of 92.3% and an error reduction of 52.8% relative to the standard procedure approach which ranked the knockout gene on average at position 17 with an AUC value of 83.7%.
In this study we could identify promising candidate genes using network based machine learning approaches even if no knowledge is available about the disease or phenotype.
对于没有先前知识(例如已知的疾病基因或疾病相关途径)的疾病,发现新的疾病基因仍然具有挑战性。进行遗传研究通常会导致大量候选基因列表,其中只有少数几个可以进行进一步研究。我们最近开发了一种用于遗传性疾病的计算方法,该方法通过用受影响和健康个体之间的差异基因表达实验数据替代先前知识,确定最有前途的候选基因。为了提高我们的优先级策略的性能,我们通过应用不同的机器学习方法扩展了我们以前的工作,这些方法通过确定基因是否被功能关联或蛋白质-蛋白质相互作用网络中高度差异表达的基因包围来识别有前途的候选基因。
我们提出了三种基于网络的机器学习方法来评分疾病候选基因的策略,例如核脊回归、热核和 Arnoldi 核逼近。为了比较目的,还计算了基于直接邻居表达的局部度量。我们在 40 个公开的小鼠敲除实验中对这些策略进行了基准测试,并根据基于候选基因差异表达水平的遗传标准程序(简单表达排序)获得的结果评估了性能。我们的结果表明,我们的四种策略可以优于该标准程序,并且使用热核扩散排序获得的最佳结果导致平均排名为 100 个基因中的 8 个,AUC 值为 92.3%,与标准程序相比,错误减少了 52.8%,该标准程序平均将敲除基因排在第 17 位,AUC 值为 83.7%。
在这项研究中,即使对疾病或表型没有任何了解,我们也可以使用基于网络的机器学习方法来识别有前途的候选基因。