Nutrigenomics Research Group, School of Public Health, UCD Conway Institute of Biomolecular & Biomedical Research, University College Dublin, Belfield, Dublin 4, Ireland.
BMC Bioinformatics. 2010 Oct 7;11:499. doi: 10.1186/1471-2105-11-499.
Currently, a number of bioinformatics methods are available to generate appropriate lists of genes from a microarray experiment. While these lists represent an accurate primary analysis of the data, fewer options exist to contextualise those lists. The development and validation of such methods is crucial to the wider application of microarray technology in the clinical setting. Two key challenges in clinical bioinformatics involve appropriate statistical modelling of dynamic transcriptomic changes, and extraction of clinically relevant meaning from very large datasets.
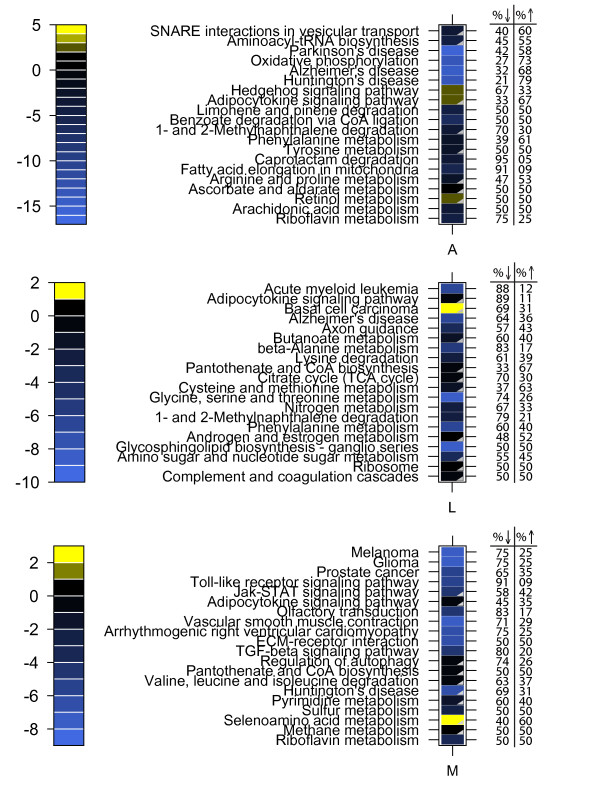
Here, we apply an approach to gene set enrichment analysis that allows for detection of bi-directional enrichment within a gene set. Furthermore, we apply canonical correlation analysis and Fisher's exact test, using plasma marker data with known clinical relevance to aid identification of the most important gene and pathway changes in our transcriptomic dataset. After a 28-day dietary intervention with high-CLA beef, a range of plasma markers indicated a marked improvement in the metabolic health of genetically obese mice. Tissue transcriptomic profiles indicated that the effects were most dramatic in liver (1270 genes significantly changed; p < 0.05), followed by muscle (601 genes) and adipose (16 genes). Results from modified GSEA showed that the high-CLA beef diet affected diverse biological processes across the three tissues, and that the majority of pathway changes reached significance only with the bi-directional test. Combining the liver tissue microarray results with plasma marker data revealed 110 CLA-sensitive genes showing strong canonical correlation with one or more plasma markers of metabolic health, and 9 significantly overrepresented pathways among this set; each of these pathways was also significantly changed by the high-CLA diet. Closer inspection of two of these pathways--selenoamino acid metabolism and steroid biosynthesis--illustrated clear diet-sensitive changes in constituent genes, as well as strong correlations between gene expression and plasma markers of metabolic syndrome independent of the dietary effect.
Bi-directional gene set enrichment analysis more accurately reflects dynamic regulatory behaviour in biochemical pathways, and as such highlighted biologically relevant changes that were not detected using a traditional approach. In such cases where transcriptomic response to treatment is exceptionally large, canonical correlation analysis in conjunction with Fisher's exact test highlights the subset of pathways showing strongest correlation with the clinical markers of interest. In this case, we have identified selenoamino acid metabolism and steroid biosynthesis as key pathways mediating the observed relationship between metabolic health and high-CLA beef. These results indicate that this type of analysis has the potential to generate novel transcriptome-based biomarkers of disease.
目前,有许多生物信息学方法可用于从微阵列实验中生成合适的基因列表。虽然这些列表代表了对数据的准确初步分析,但用于上下文化这些列表的方法却很少。这些方法的开发和验证对于将微阵列技术更广泛地应用于临床环境至关重要。临床生物信息学中的两个关键挑战涉及对动态转录组变化进行适当的统计建模,以及从非常大数据集中提取临床相关的意义。
在这里,我们应用了一种基因集富集分析方法,该方法允许在基因集中检测双向富集。此外,我们应用典型相关分析和 Fisher 精确检验,使用具有已知临床相关性的血浆标记物数据来帮助确定我们转录组数据集中最重要的基因和途径变化。在高 CLA 牛肉的 28 天饮食干预后,一系列血浆标记物表明遗传肥胖小鼠的代谢健康状况明显改善。组织转录组谱表明,这些影响在肝脏中最为明显(1270 个基因显著变化;p < 0.05),其次是肌肉(601 个基因)和脂肪(16 个基因)。经过修正的 GSEA 结果表明,高 CLA 牛肉饮食影响了三种组织中的多种生物学过程,并且只有通过双向测试,大多数途径变化才达到显著水平。将肝组织微阵列结果与血浆标记物数据相结合,揭示了 110 个 CLA 敏感基因,这些基因与一种或多种代谢健康的血浆标记物具有很强的典型相关性,并且在该集合中存在 9 个显著过表达的途径;这些途径中的每一个也都受到高 CLA 饮食的显著影响。对其中两个途径 - 硒代氨基酸代谢和类固醇生物合成的仔细检查表明,组成基因的饮食敏感性变化明显,并且基因表达与代谢综合征的血浆标记物之间存在很强的相关性,而与饮食效应无关。
双向基因集富集分析更准确地反映了生化途径中的动态调节行为,因此突出了使用传统方法无法检测到的生物学相关变化。在这种情况下,治疗的转录组反应异常大,典型相关分析与 Fisher 精确检验相结合突出了与感兴趣的临床标记物相关性最强的途径子集。在这种情况下,我们已经确定硒代氨基酸代谢和类固醇生物合成是介导观察到的代谢健康与高 CLA 牛肉之间关系的关键途径。这些结果表明,这种类型的分析有可能产生新的基于转录组的疾病生物标志物。