Friedrich Miescher Laboratory, Max Planck Society, Spemannstr, 39, 72076 Tübingen, Germany.
BMC Bioinformatics. 2010 Oct 26;11 Suppl 8(Suppl 8):S5. doi: 10.1186/1471-2105-11-S8-S5.
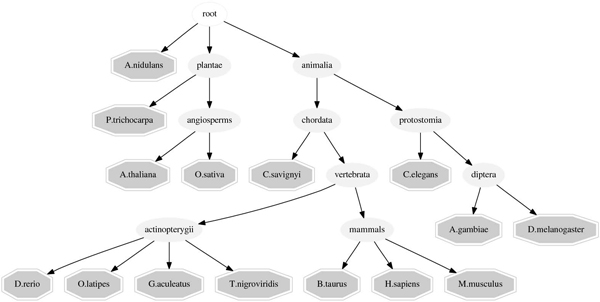
The lack of sufficient training data is the limiting factor for many Machine Learning applications in Computational Biology. If data is available for several different but related problem domains, Multitask Learning algorithms can be used to learn a model based on all available information. In Bioinformatics, many problems can be cast into the Multitask Learning scenario by incorporating data from several organisms. However, combining information from several tasks requires careful consideration of the degree of similarity between tasks. Our proposed method simultaneously learns or refines the similarity between tasks along with the Multitask Learning classifier. This is done by formulating the Multitask Learning problem as Multiple Kernel Learning, using the recently published q-Norm MKL algorithm.
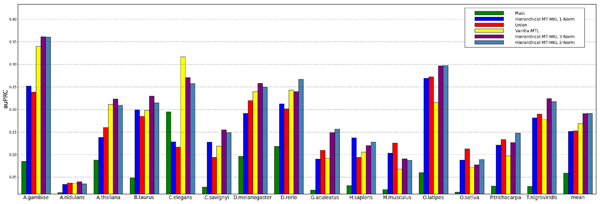
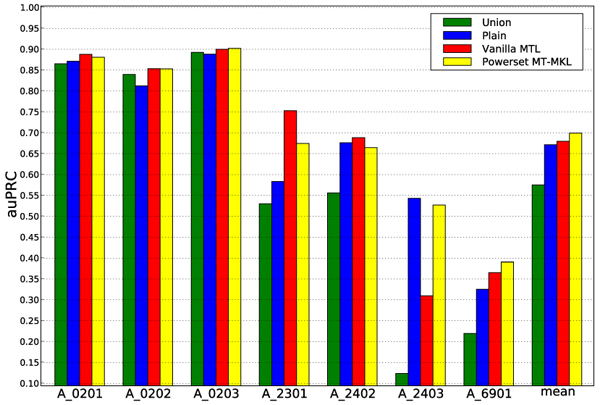
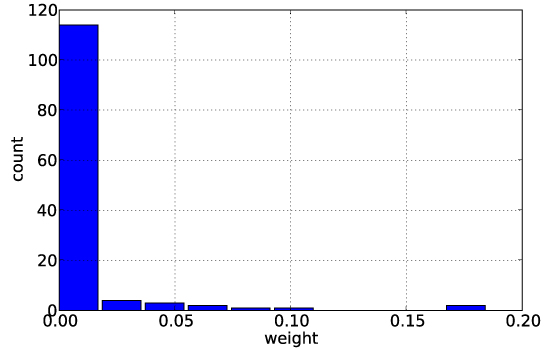
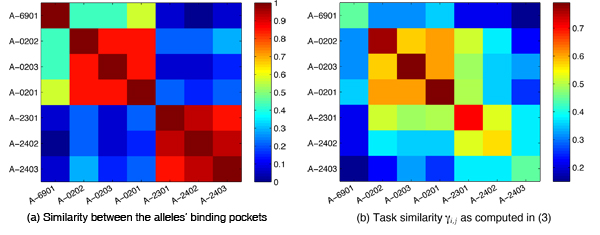
We demonstrate the performance of our method on two problems from Computational Biology. First, we show that our method is able to improve performance on a splice site dataset with given hierarchical task structure by refining the task relationships. Second, we consider an MHC-I dataset, for which we assume no knowledge about the degree of task relatedness. Here, we are able to learn the task similarities ab initio along with the Multitask classifiers. In both cases, we outperform baseline methods that we compare against.
We present a novel approach to Multitask Learning that is capable of learning task similarity along with the classifiers. The framework is very general as it allows to incorporate prior knowledge about tasks relationships if available, but is also able to identify task similarities in absence of such prior information. Both variants show promising results in applications from Computational Biology.
对于计算生物学中的许多机器学习应用,缺乏足够的训练数据是一个限制因素。如果有多个不同但相关的问题领域的数据可用,则可以使用多任务学习算法来学习基于所有可用信息的模型。在生物信息学中,许多问题可以通过合并来自多个生物体的数据来归入多任务学习场景。但是,合并来自多个任务的信息需要仔细考虑任务之间的相似程度。我们提出的方法通过将多任务学习问题表述为多核学习,并使用最近发布的 q-Norm MKL 算法,同时学习或改进任务之间的相似性和多任务学习分类器。
我们在计算生物学中的两个问题上展示了我们方法的性能。首先,我们表明,通过改进任务关系,我们的方法能够提高给定层次任务结构的剪接位点数据集的性能。其次,我们考虑了 MHC-I 数据集,对于该数据集,我们假设对任务相关性的程度一无所知。在这里,我们能够在学习多任务分类器的同时学习任务相似性。在这两种情况下,我们的表现都优于我们比较的基准方法。
我们提出了一种新的多任务学习方法,能够与分类器一起学习任务相似性。该框架非常通用,因为它允许在有可用的情况下纳入关于任务关系的先验知识,但也能够在没有这种先验信息的情况下识别任务相似性。两种变体在计算生物学中的应用中都显示出了有前途的结果。