Center for Bioinformatics, Eberhard-Karls-Universität, Sand 14, 72076 Tübingen, Germany.
BMC Bioinformatics. 2010 Oct 26;11 Suppl 8(Suppl 8):S7. doi: 10.1186/1471-2105-11-S8-S7.
String kernels are commonly used for the classification of biological sequences, nucleotide as well as amino acid sequences. Although string kernels are already very powerful, when it comes to amino acids they have a major short coming. They ignore an important piece of information when comparing amino acids: the physico-chemical properties such as size, hydrophobicity, or charge. This information is very valuable, especially when training data is less abundant. There have been only very few approaches so far that aim at combining these two ideas.
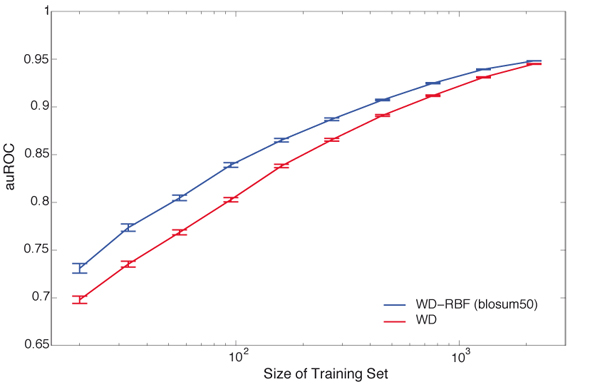
We propose new string kernels that combine the benefits of physico-chemical descriptors for amino acids with the ones of string kernels. The benefits of the proposed kernels are assessed on two problems: MHC-peptide binding classification using position specific kernels and protein classification based on the substring spectrum of the sequences. Our experiments demonstrate that the incorporation of amino acid properties in string kernels yields improved performances compared to standard string kernels and to previously proposed non-substring kernels.
In summary, the proposed modifications, in particular the combination with the RBF substring kernel, consistently yield improvements without affecting the computational complexity. The proposed kernels therefore appear to be the kernels of choice for any protein sequence-based inference.
Data sets, code and additional information are available from http://www.fml.tuebingen.mpg.de/raetsch/suppl/aask. Implementations of the developed kernels are available as part of the Shogun toolbox.
字符串核函数常用于生物序列(核苷酸和氨基酸序列)的分类。尽管字符串核函数已经非常强大,但在处理氨基酸时,它们存在一个主要的缺点。在比较氨基酸时,它们忽略了一个重要信息:理化性质,如大小、疏水性或电荷。这些信息非常有价值,特别是在训练数据较少的情况下。到目前为止,只有极少数方法旨在结合这两个想法。
我们提出了新的字符串核函数,将氨基酸的理化描述符的优势与字符串核函数的优势相结合。所提出的核函数的优势在两个问题上进行了评估:基于位置特定核函数的 MHC-肽结合分类和基于序列子串谱的蛋白质分类。我们的实验表明,将氨基酸性质纳入字符串核函数可提高性能,与标准字符串核函数和之前提出的非子串核函数相比。
总之,所提出的修改,特别是与 RBF 子串核函数的结合,在不影响计算复杂度的情况下,始终能提高性能。因此,所提出的核函数似乎是任何基于蛋白质序列的推理的首选核函数。
数据集、代码和其他信息可从 http://www.fml.tuebingen.mpg.de/raetsch/suppl/aask 获得。所开发的核函数的实现可作为 Shogun 工具箱的一部分获得。