Spänig Sebastian, Heider Dominik
Department of Bioinformatics, Faculty of Mathematics and Computer Science, Philipps-University of Marburg, Marburg, Germany.
BioData Min. 2019 Mar 4;12:7. doi: 10.1186/s13040-019-0196-x. eCollection 2019.
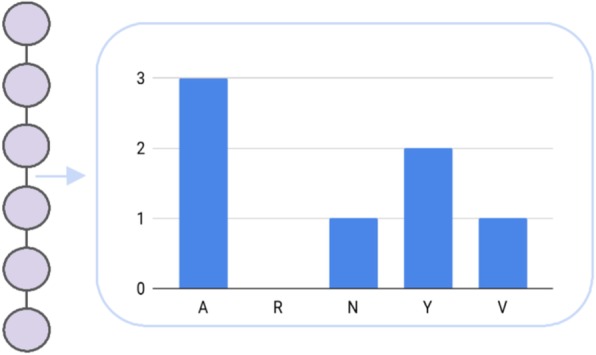
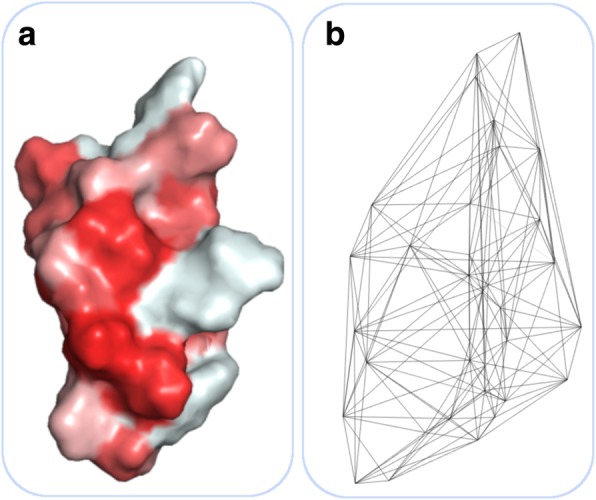
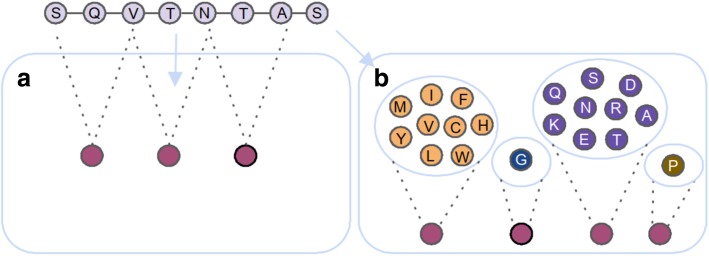
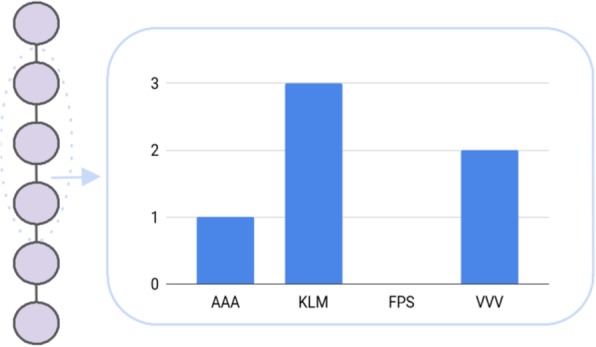
Antimicrobial peptides (AMPs) are part of the inherent immune system. In fact, they occur in almost all organisms including, e.g., plants, animals, and humans. Remarkably, they show effectivity also against multi-resistant pathogens with a high selectivity. This is especially crucial in times, where society is faced with the major threat of an ever-increasing amount of antibiotic resistant microbes. In addition, AMPs can also exhibit antitumor and antiviral effects, thus a variety of scientific studies dealt with the prediction of active peptides in recent years. Due to their potential, even the pharmaceutical industry is keen on discovering and developing novel AMPs. However, AMPs are difficult to verify in vitro, hence researchers conduct sequence similarity experiments against known, active peptides. Unfortunately, this approach is very time-consuming and limits potential candidates to sequences with a high similarity to known AMPs. Machine learning methods offer the opportunity to explore the huge space of sequence variations in a timely manner. These algorithms have, in principal, paved the way for an automated discovery of AMPs. However, machine learning models require a numerical input, thus an informative encoding is very important. Unfortunately, developing an appropriate encoding is a major challenge, which has not been entirely solved so far. For this reason, the development of novel amino acid encodings is established as a stand-alone research branch. The present review introduces state-of-the-art encodings of amino acids as well as their properties in sequence and structure based aggregation. Moreover, albeit a well-chosen encoding is essential, performant classifiers are required, which is reflected by a tendency towards specifically designed models in the literature. Furthermore, we introduce these models with a particular focus on encodings derived from support vector machines and deep learning approaches. Albeit a strong focus has been set on AMP predictions, not all of the mentioned encodings have been elaborated as part of antimicrobial research studies, but rather as general protein or peptide representations.
抗菌肽(AMPs)是固有免疫系统的一部分。事实上,它们几乎存在于所有生物体中,包括植物、动物和人类等。值得注意的是,它们对多重耐药病原体也具有高效性且选择性高。在当今社会面临日益增多的抗生素耐药微生物这一重大威胁的时代,这一点尤为关键。此外,抗菌肽还可表现出抗肿瘤和抗病毒作用,因此近年来有各种科学研究致力于预测活性肽。由于其潜力,就连制药行业也热衷于发现和开发新型抗菌肽。然而,抗菌肽在体外难以验证,因此研究人员针对已知的活性肽进行序列相似性实验。不幸的是,这种方法非常耗时,并且将潜在候选物限制在与已知抗菌肽高度相似的序列上。机器学习方法提供了及时探索巨大序列变异空间的机会。这些算法原则上为抗菌肽的自动发现铺平了道路。然而,机器学习模型需要数值输入,因此信息编码非常重要。不幸的是,开发合适的编码是一项重大挑战,到目前为止尚未完全解决。因此,新型氨基酸编码的开发已成为一个独立的研究分支。本综述介绍了氨基酸的最新编码及其在基于序列和结构的聚集中的特性。此外,尽管精心选择的编码至关重要,但还需要性能良好的分类器,这一点在文献中倾向于专门设计的模型中有所体现。此外,我们特别介绍了这些模型,重点是源自支持向量机和深度学习方法的编码。尽管重点一直放在抗菌肽预测上,但并非所有提到的编码都是作为抗菌研究的一部分进行阐述的,而是作为一般蛋白质或肽的表示形式。