Genetic and Genomic Epidemiology Unit, Wellcome Trust Centre for Human Genetics, University of Oxford, Oxford, UK.
Nat Protoc. 2010 Sep;5(9):1564-73. doi: 10.1038/nprot.2010.116. Epub 2010 Aug 26.
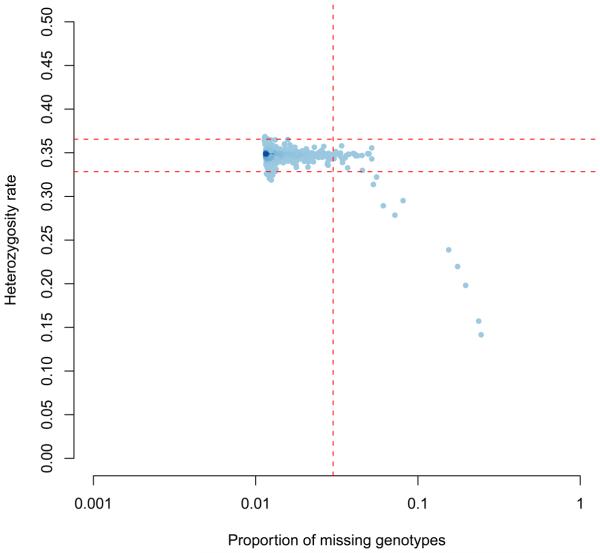
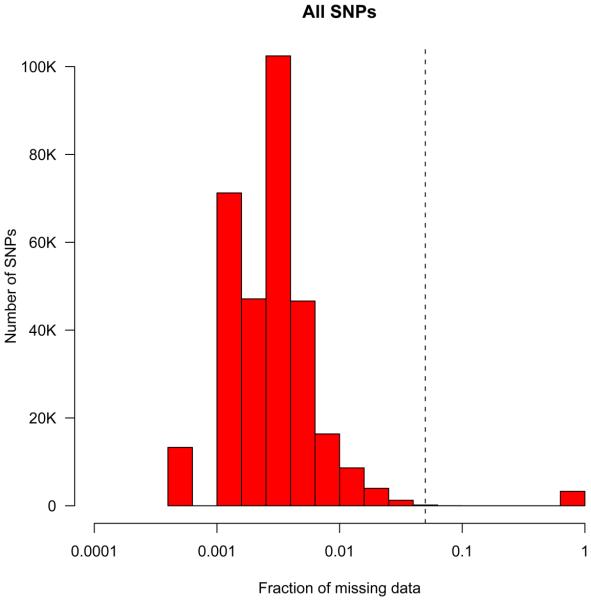
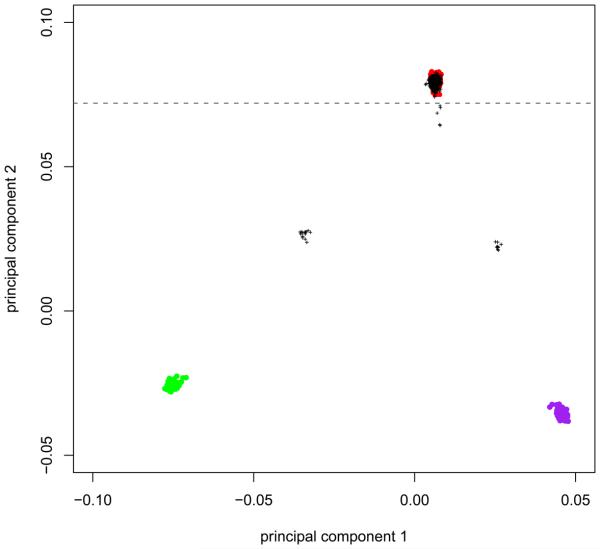
This protocol details the steps for data quality assessment and control that are typically carried out during case-control association studies. The steps described involve the identification and removal of DNA samples and markers that introduce bias. These critical steps are paramount to the success of a case-control study and are necessary before statistically testing for association. We describe how to use PLINK, a tool for handling SNP data, to perform assessments of failure rate per individual and per SNP and to assess the degree of relatedness between individuals. We also detail other quality-control procedures, including the use of SMARTPCA software for the identification of ancestral outliers. These platforms were selected because they are user-friendly, widely used and computationally efficient. Steps needed to detect and establish a disease association using case-control data are not discussed here. Issues concerning study design and marker selection in case-control studies have been discussed in our earlier protocols. This protocol, which is routinely used in our labs, should take approximately 8 h to complete.
本方案详细介绍了病例对照关联研究中通常进行的数据质量评估和控制步骤。所描述的步骤涉及鉴定和去除引入偏倚的 DNA 样本和标记物。这些关键步骤对于病例对照研究的成功至关重要,并且在进行关联的统计检验之前是必要的。我们描述了如何使用 PLINK,一种用于处理 SNP 数据的工具,来执行个体和 SNP 的失效率评估,并评估个体之间的亲缘关系程度。我们还详细介绍了其他质量控制程序,包括使用 SMARTPCA 软件识别祖先异常值。选择这些平台是因为它们易于使用、广泛使用且计算效率高。本方案未讨论使用病例对照数据检测和建立疾病关联所需的步骤。病例对照研究中有关研究设计和标记选择的问题已在我们之前的方案中讨论过。本方案在我们的实验室中经常使用,大约需要 8 小时才能完成。