National Center for Biotechnology Information, US National Library of Medicine, 8600 Rockville Pike, Bethesda, MD 20894, USA.
J Biomed Inform. 2011 Apr;44(2):310-8. doi: 10.1016/j.jbi.2010.11.001. Epub 2010 Nov 20.
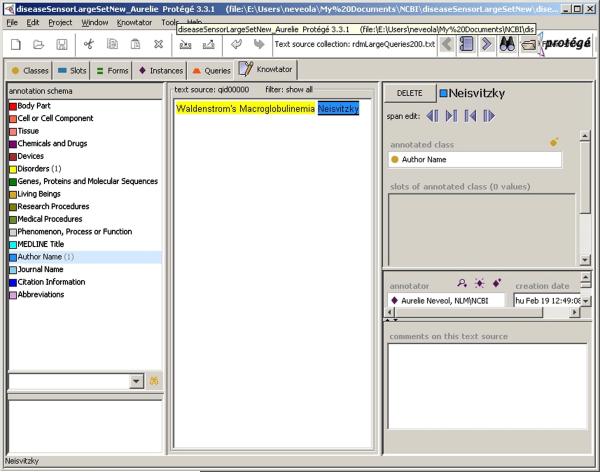
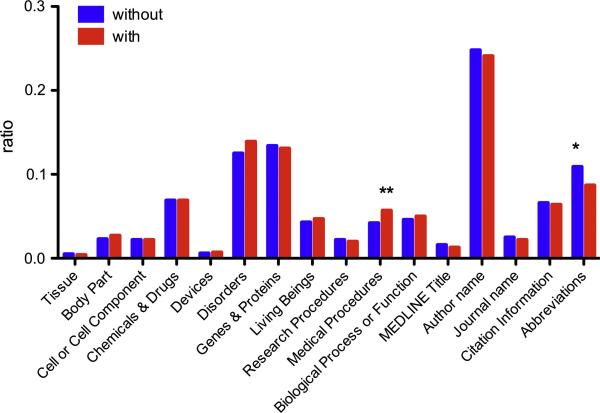
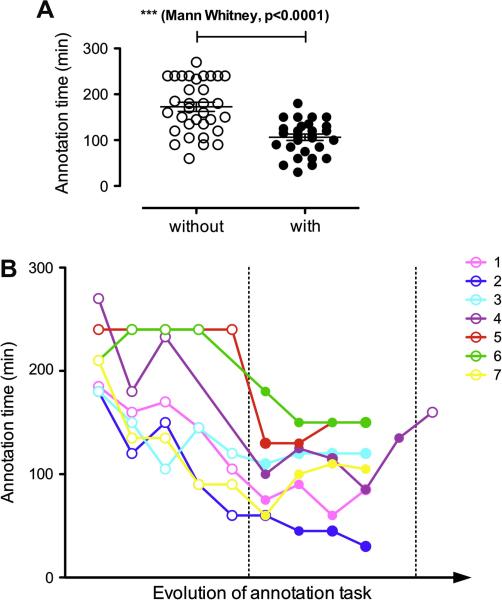
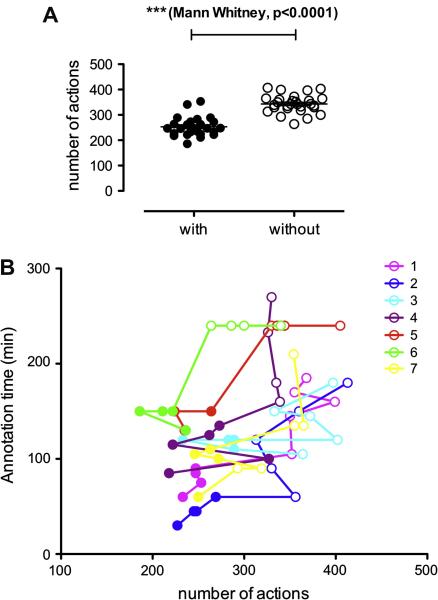
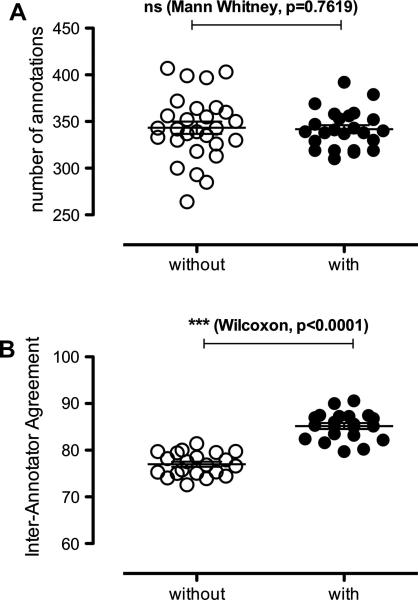
Information processing algorithms require significant amounts of annotated data for training and testing. The availability of such data is often hindered by the complexity and high cost of production. In this paper, we investigate the benefits of a state-of-the-art tool to help with the semantic annotation of a large set of biomedical queries. Seven annotators were recruited to annotate a set of 10,000 PubMed® queries with 16 biomedical and bibliographic categories. About half of the queries were annotated from scratch, while the other half were automatically pre-annotated and manually corrected. The impact of the automatic pre-annotations was assessed on several aspects of the task: time, number of actions, annotator satisfaction, inter-annotator agreement, quality and number of the resulting annotations. The analysis of annotation results showed that the number of required hand annotations is 28.9% less when using pre-annotated results from automatic tools. As a result, the overall annotation time was substantially lower when pre-annotations were used, while inter-annotator agreement was significantly higher. In addition, there was no statistically significant difference in the semantic distribution or number of annotations produced when pre-annotations were used. The annotated query corpus is freely available to the research community. This study shows that automatic pre-annotations are found helpful by most annotators. Our experience suggests using an automatic tool to assist large-scale manual annotation projects. This helps speed-up the annotation time and improve annotation consistency while maintaining high quality of the final annotations.
信息处理算法需要大量经过注释的数据进行训练和测试。然而,这种数据的可用性往往受到数据生产的复杂性和高成本的限制。在本文中,我们研究了一种最先进的工具,以帮助对大量生物医学查询进行语义注释。我们招募了 7 名注释者对 10000 个 PubMed®查询进行注释,涵盖 16 个生物医学和书目类别。约一半的查询是从头开始注释的,而另一半则是自动预注释和手动纠正的。评估了自动预注释在任务的几个方面的影响:时间、操作数量、注释者满意度、注释者间一致性、注释质量和数量。分析注释结果表明,使用自动工具的预注释结果可将所需的人工注释数量减少 28.9%。因此,使用预注释可以显著减少整体注释时间,同时显著提高注释者间的一致性。此外,使用预注释不会导致语义分布或生成的注释数量产生统计学上的显著差异。已注释的查询语料库可供研究界自由使用。这项研究表明,大多数注释者认为自动预注释是有帮助的。我们的经验表明,使用自动工具可以辅助大规模的手动注释项目。这有助于加快注释时间,提高注释的一致性,同时保持最终注释的高质量。