Hong Simon, Hikosaka Okihide
Laboratory of Sensorimotor Research, National Eye Institute, National Institutes of Health Bethesda, MD, USA.
Front Behav Neurosci. 2011 Mar 21;5:15. doi: 10.3389/fnbeh.2011.00015. eCollection 2011.
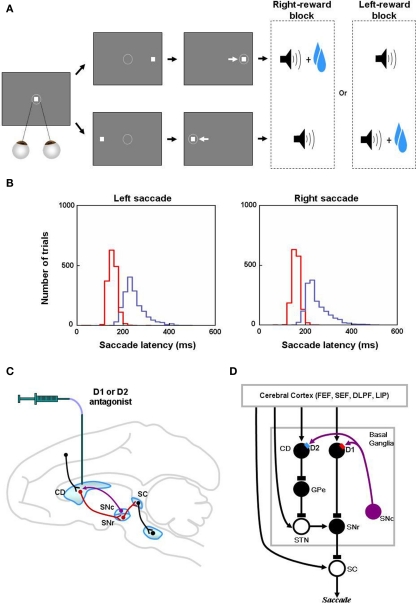
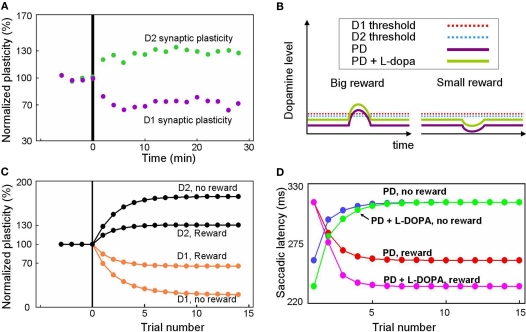
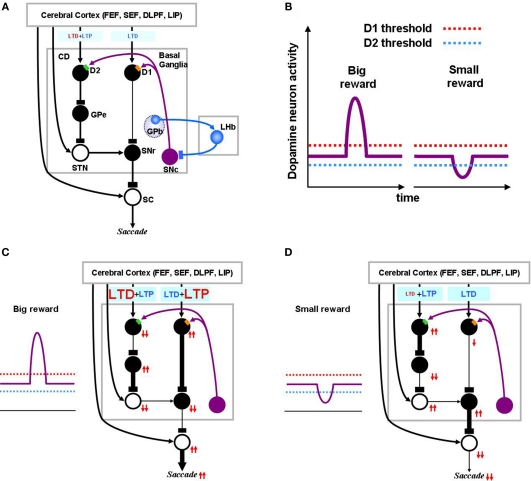
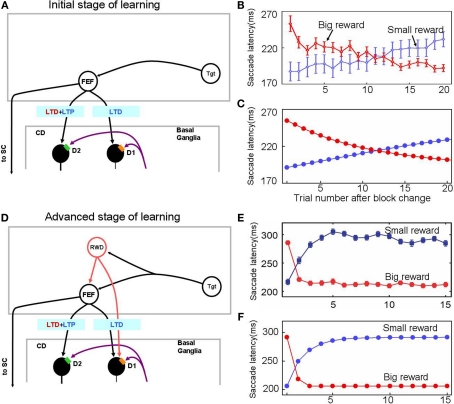
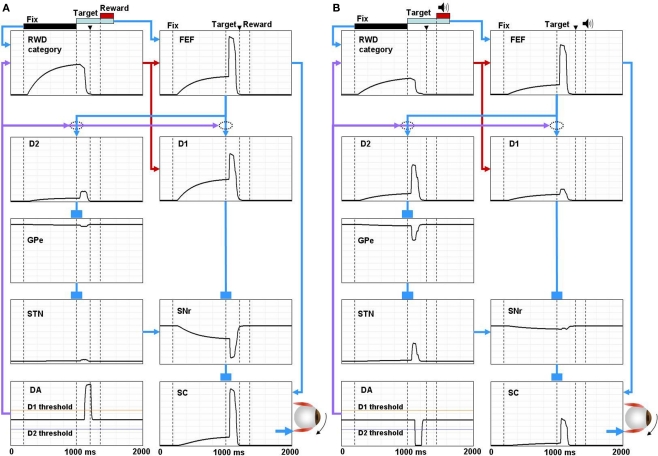
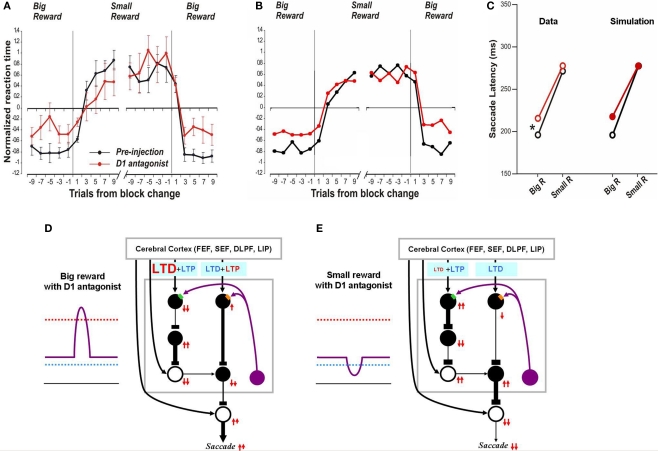
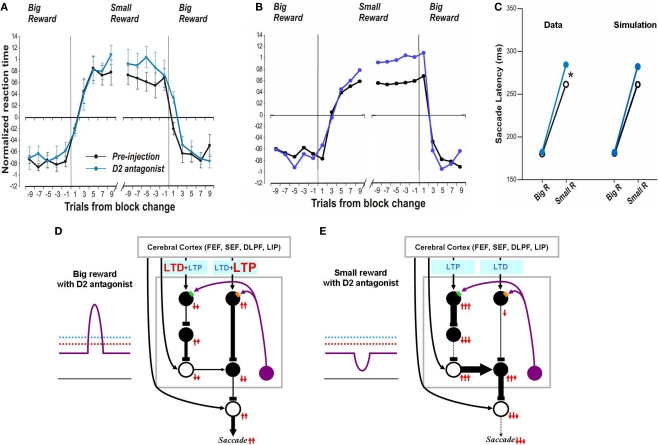
The basal ganglia are thought to play a crucial role in reinforcement learning. Central to the learning mechanism are dopamine (DA) D1 and D2 receptors located in the cortico-striatal synapses. However, it is still unclear how this DA-mediated synaptic plasticity is deployed and coordinated during reward-contingent behavioral changes. Here we propose a computational model of reinforcement learning that uses different thresholds of D1- and D2-mediated synaptic plasticity which are antagonized by DA-independent synaptic plasticity. A phasic increase in DA release caused by a larger-than-expected reward induces long-term potentiation (LTP) in the direct pathway, whereas a phasic decrease in DA release caused by a smaller-than-expected reward induces a cessation of long-term depression, leading to LTP in the indirect pathway. This learning mechanism can explain the robust behavioral adaptation observed in a location-reward-value-association task where the animal makes shorter latency saccades to reward locations. The changes in saccade latency become quicker as the monkey becomes more experienced. This behavior can be explained by a switching mechanism which activates the cortico-striatal circuit selectively. Our model also shows how D1- or D2-receptor blocking experiments affect selectively either reward or no-reward trials. The proposed mechanisms also explain the behavioral changes in Parkinson's disease.
基底神经节被认为在强化学习中起着关键作用。学习机制的核心是位于皮质 - 纹状体突触的多巴胺(DA)D1和D2受体。然而,在奖励相关的行为变化过程中,这种多巴胺介导的突触可塑性是如何部署和协调的,目前仍不清楚。在此,我们提出一种强化学习的计算模型,该模型使用由独立于多巴胺的突触可塑性拮抗的D1和D2介导的突触可塑性的不同阈值。由大于预期的奖励引起的多巴胺释放的阶段性增加会在直接通路中诱导长时程增强(LTP),而由小于预期的奖励引起的多巴胺释放的阶段性减少会导致长时延抑制的停止,从而在间接通路中诱导长时程增强。这种学习机制可以解释在位置 - 奖励 - 价值关联任务中观察到的强大行为适应性,在该任务中动物向奖励位置做出的扫视潜伏期更短。随着猴子经验的增加,扫视潜伏期的变化会变得更快。这种行为可以通过一种选择性激活皮质 - 纹状体回路的切换机制来解释。我们的模型还展示了D1或D2受体阻断实验如何选择性地影响奖励或无奖励试验。所提出的机制也解释了帕金森病中的行为变化。