Merck Research Laboratories, Department of Molecular Pharmacology, Oss, The Netherlands.
BMC Bioinformatics. 2011 Apr 12;12:94. doi: 10.1186/1471-2105-12-94.
Designing maximally selective ligands that act on individual targets is the dominant paradigm in drug discovery. Poor selectivity can underlie toxicity and side effects in the clinic, and for this reason compound selectivity is increasingly monitored from very early on in the drug discovery process. To make sense of large amounts of profiling data, and to determine when a compound is sufficiently selective, there is a need for a proper quantitative measure of selectivity.
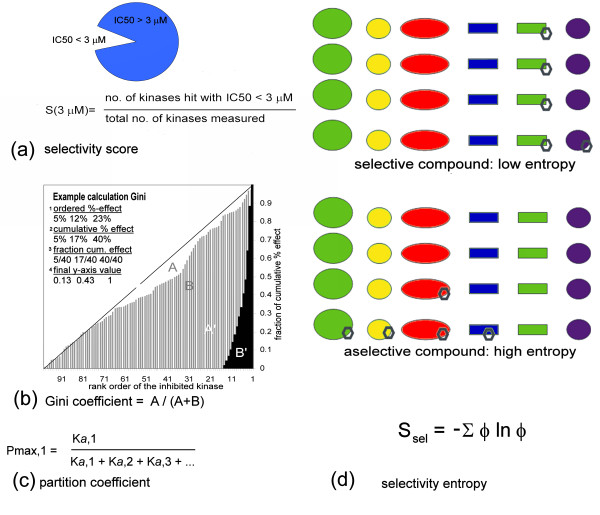
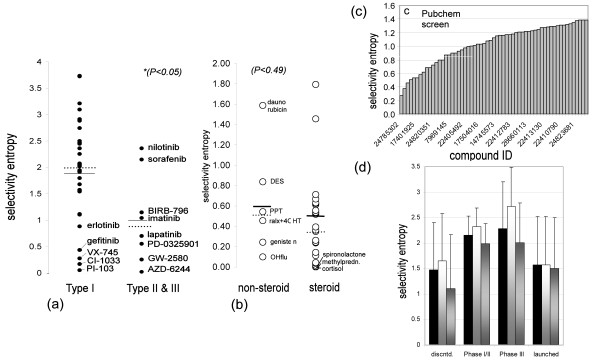
Here we propose a new theoretical entropy score that can be calculated from a set of IC(50) data. In contrast to previous measures such as the 'selectivity score', Gini score, or partition index, the entropy score is non-arbitary, fully exploits IC(50) data, and is not dependent on a reference enzyme. In addition, the entropy score gives the most robust values with data from different sources, because it is less sensitive to errors. We apply the new score to kinase and nuclear receptor profiling data, and to high-throughput screening data. In addition, through analyzing profiles of clinical compounds, we show quantitatively that a more selective kinase inhibitor is not necessarily more drug-like.
For quantifying selectivity from panel profiling, a theoretical entropy score is the best method. It is valuable for studying the molecular mechanisms of selectivity, and to steer compound progression in drug discovery programs.
设计针对单个靶点的最大选择性配体是药物发现的主要范例。选择性差可能导致临床毒性和副作用,因此化合物的选择性越来越受到关注,并在药物发现过程的早期就进行监测。为了理解大量的分析数据,并确定化合物的选择性是否足够,需要有一种适当的定量选择性测量方法。
在这里,我们提出了一种新的理论熵评分,可以从一组 IC50 数据中计算得出。与以前的测量方法(如选择性评分、基尼评分或分区指数)不同,熵评分是不随意的,充分利用了 IC50 数据,并且不依赖于参考酶。此外,由于对误差的敏感性较低,熵评分在来自不同来源的数据中给出了最稳健的值。我们将新评分应用于激酶和核受体分析数据以及高通量筛选数据。此外,通过分析临床化合物的谱,我们定量地表明,更具选择性的激酶抑制剂不一定更具类药性。
对于从面板分析中定量选择性,理论熵评分是最佳方法。它对于研究选择性的分子机制以及指导药物发现计划中的化合物进展具有重要价值。