Department of Computer Science, University of Sheffield, Sheffield, United Kingdom.
PLoS One. 2011 May 4;6(5):e18539. doi: 10.1371/journal.pone.0018539.
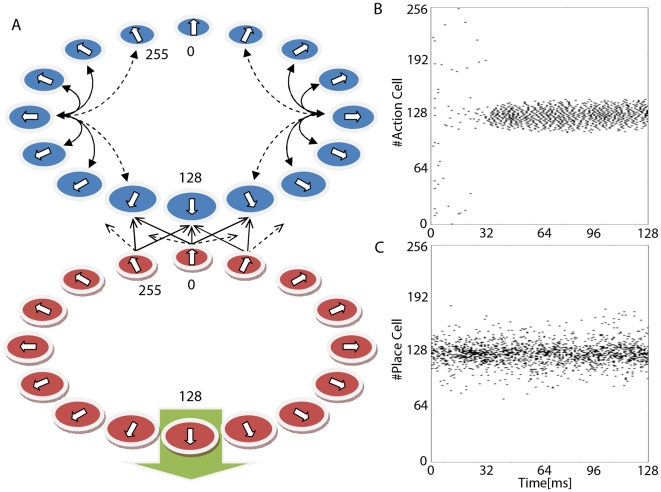
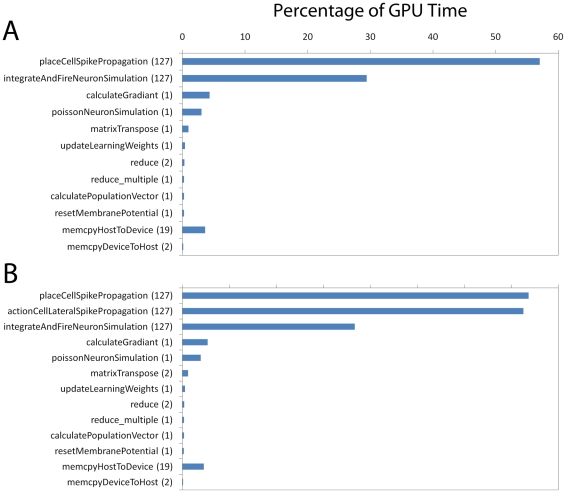
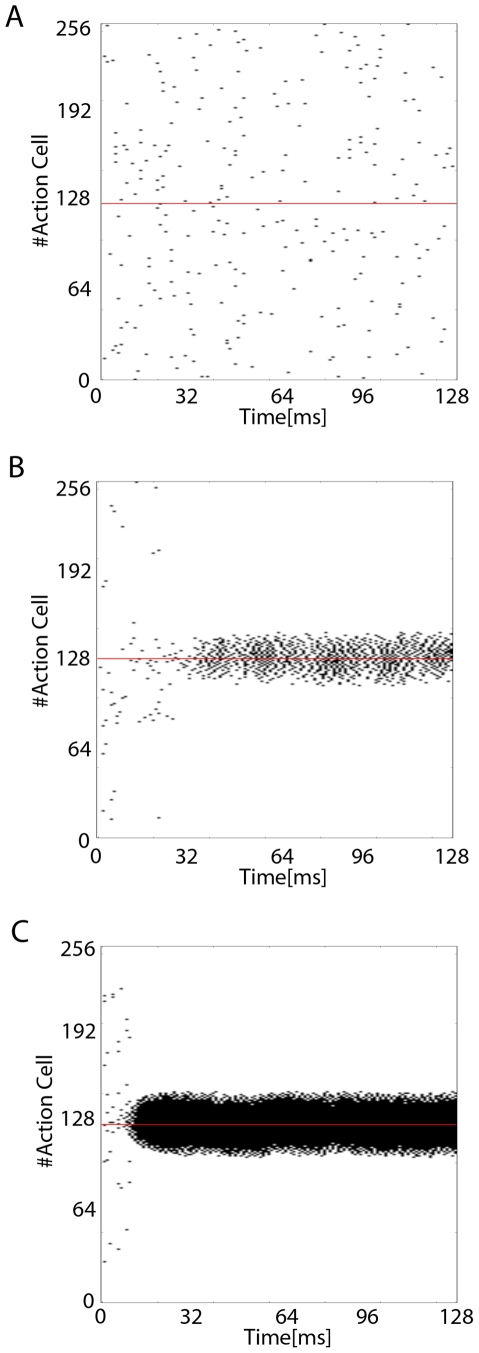
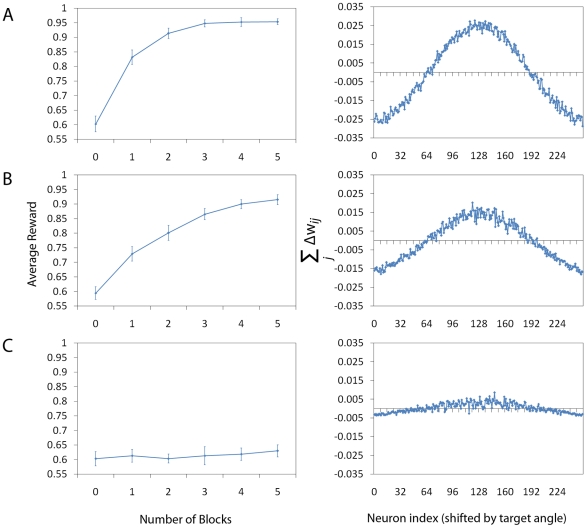
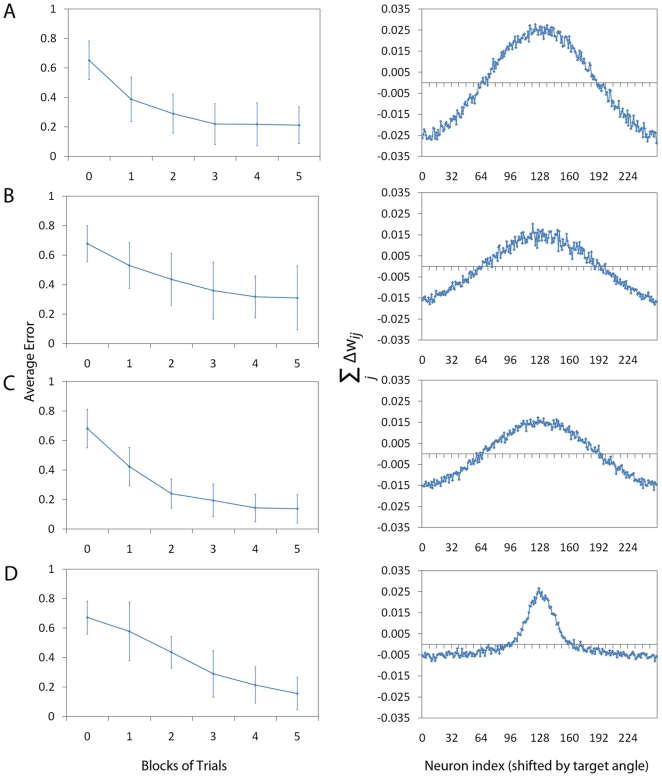
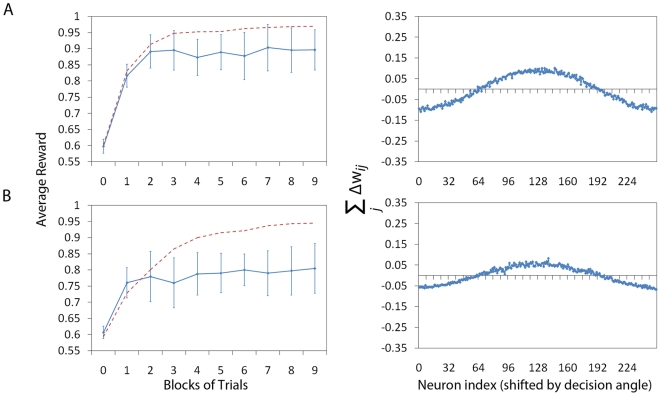
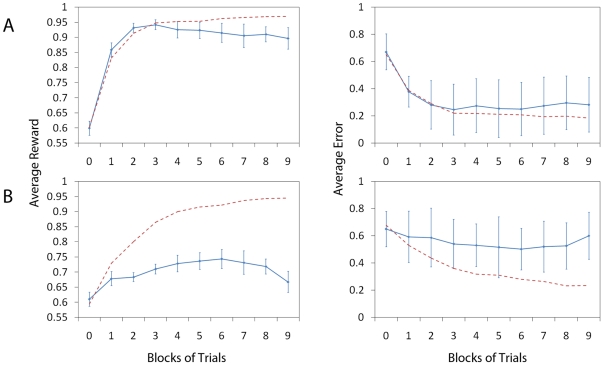
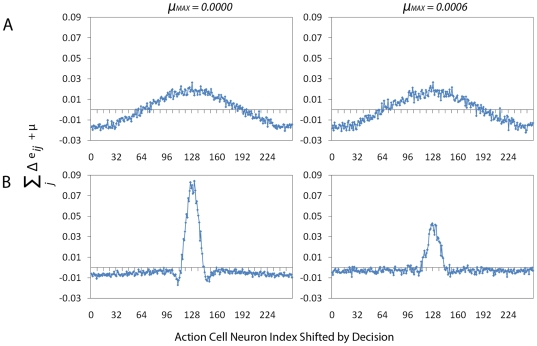
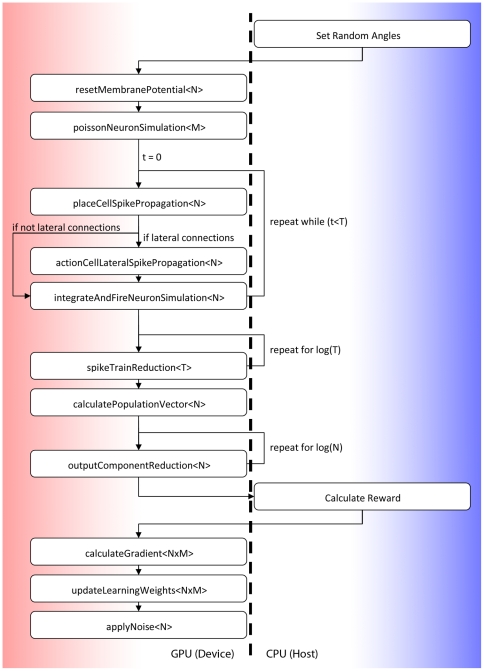
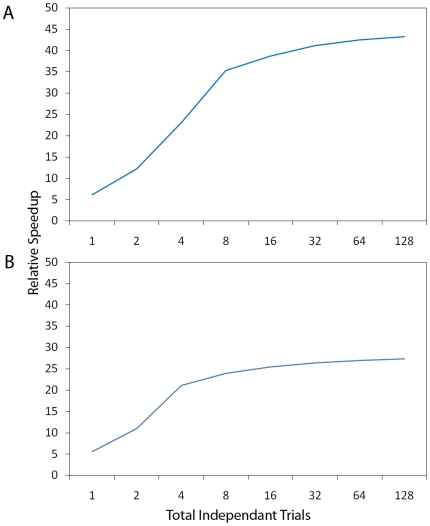
High performance computing on the Graphics Processing Unit (GPU) is an emerging field driven by the promise of high computational power at a low cost. However, GPU programming is a non-trivial task and moreover architectural limitations raise the question of whether investing effort in this direction may be worthwhile. In this work, we use GPU programming to simulate a two-layer network of Integrate-and-Fire neurons with varying degrees of recurrent connectivity and investigate its ability to learn a simplified navigation task using a policy-gradient learning rule stemming from Reinforcement Learning. The purpose of this paper is twofold. First, we want to support the use of GPUs in the field of Computational Neuroscience. Second, using GPU computing power, we investigate the conditions under which the said architecture and learning rule demonstrate best performance. Our work indicates that networks featuring strong Mexican-Hat-shaped recurrent connections in the top layer, where decision making is governed by the formation of a stable activity bump in the neural population (a "non-democratic" mechanism), achieve mediocre learning results at best. In absence of recurrent connections, where all neurons "vote" independently ("democratic") for a decision via population vector readout, the task is generally learned better and more robustly. Our study would have been extremely difficult on a desktop computer without the use of GPU programming. We present the routines developed for this purpose and show that a speed improvement of 5x up to 42x is provided versus optimised Python code. The higher speed is achieved when we exploit the parallelism of the GPU in the search of learning parameters. This suggests that efficient GPU programming can significantly reduce the time needed for simulating networks of spiking neurons, particularly when multiple parameter configurations are investigated.
基于图形处理单元 (GPU) 的高性能计算是一个新兴领域,其承诺以低成本提供高计算能力。然而,GPU 编程是一项非平凡的任务,而且架构限制提出了这样一个问题,即投入精力朝这个方向发展是否值得。在这项工作中,我们使用 GPU 编程来模拟具有不同程度递归连接的两层积分点火神经元网络,并使用源自强化学习的策略梯度学习规则来研究其学习简化导航任务的能力。本文的目的有两个。首先,我们希望支持在计算神经科学领域使用 GPU。其次,使用 GPU 计算能力,我们研究了在什么条件下,上述架构和学习规则可以表现出最佳性能。我们的工作表明,在顶层具有强墨西哥帽形递归连接的网络中,决策由神经元群体中稳定活动峰的形成(“非民主”机制)来控制,其学习效果充其量只是中等。在没有递归连接的情况下,所有神经元通过群体向量读出独立地(“民主”)对决策进行投票,任务通常可以更好、更稳健地学习。如果不使用 GPU 编程,我们在台式计算机上进行这项研究将极其困难。我们介绍了为此目的开发的例程,并展示了与经过优化的 Python 代码相比,速度提高了 5 倍至 42 倍。当我们在搜索学习参数时利用 GPU 的并行性时,速度会更快。这表明,高效的 GPU 编程可以大大减少模拟尖峰神经元网络所需的时间,特别是在研究多个参数配置时。