National Centre for Text Mining, Manchester Interdisciplinary Biocentre, University of Manchester, Manchester, United Kingdom.
PLoS One. 2011;6(5):e20181. doi: 10.1371/journal.pone.0020181. Epub 2011 May 25.
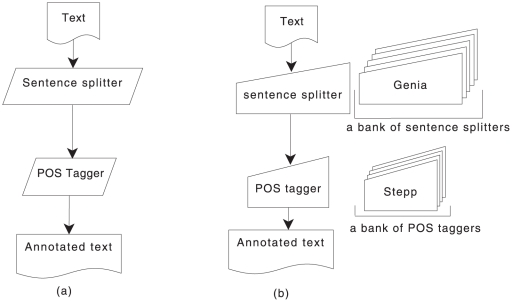
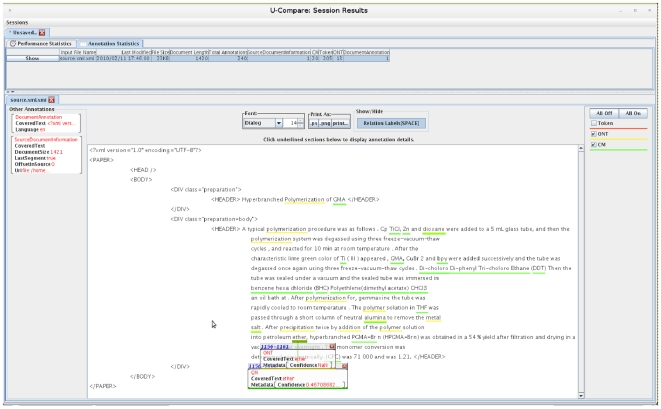
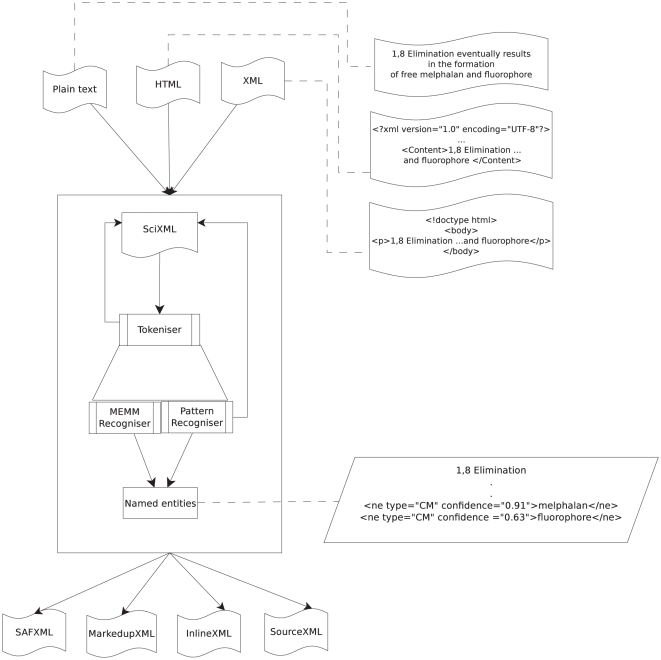
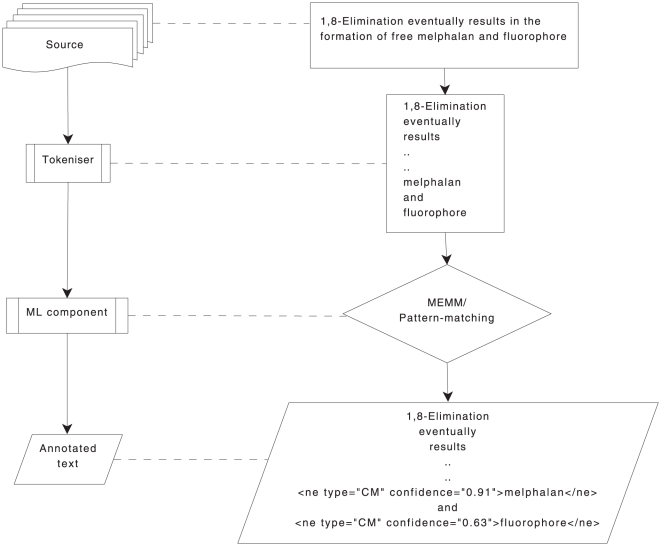
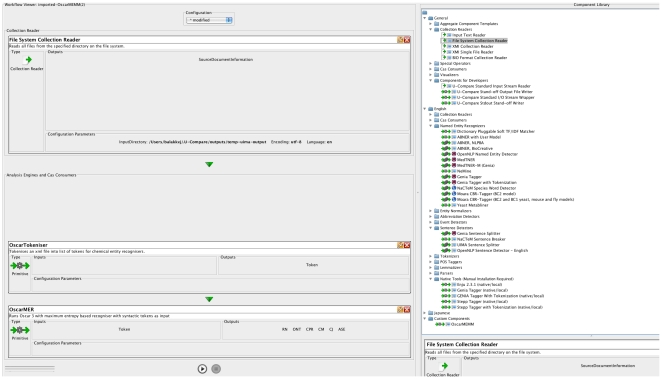
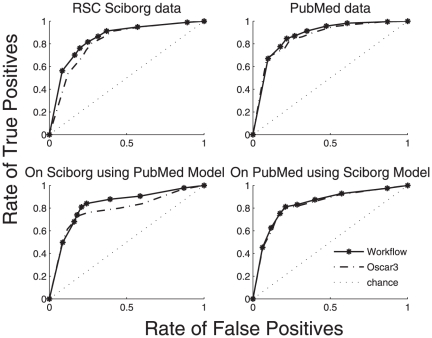
Chemistry text mining tools should be interoperable and adaptable regardless of system-level implementation, installation or even programming issues. We aim to abstract the functionality of these tools from the underlying implementation via reconfigurable workflows for automatically identifying chemical names. To achieve this, we refactored an established named entity recogniser (in the chemistry domain), OSCAR and studied the impact of each component on the net performance. We developed two reconfigurable workflows from OSCAR using an interoperable text mining framework, U-Compare. These workflows can be altered using the drag-&-drop mechanism of the graphical user interface of U-Compare. These workflows also provide a platform to study the relationship between text mining components such as tokenisation and named entity recognition (using maximum entropy Markov model (MEMM) and pattern recognition based classifiers). Results indicate that, for chemistry in particular, eliminating noise generated by tokenisation techniques lead to a slightly better performance than others, in terms of named entity recognition (NER) accuracy. Poor tokenisation translates into poorer input to the classifier components which in turn leads to an increase in Type I or Type II errors, thus, lowering the overall performance. On the Sciborg corpus, the workflow based system, which uses a new tokeniser whilst retaining the same MEMM component, increases the F-score from 82.35% to 84.44%. On the PubMed corpus, it recorded an F-score of 84.84% as against 84.23% by OSCAR.
化学文本挖掘工具应具有互操作性和可适应性,无论系统级实现、安装甚至编程问题如何。我们旨在通过可重新配置的工作流程,从底层实现中抽象出这些工具的功能,以自动识别化学名称。为此,我们重构了一个已建立的命名实体识别器(在化学领域),OSCAR,并研究了每个组件对网络性能的影响。我们使用可互操作的文本挖掘框架 U-Compare 从 OSCAR 开发了两个可重新配置的工作流程。这些工作流程可以使用 U-Compare 的图形用户界面的拖放机制进行更改。这些工作流程还提供了一个平台,可以研究文本挖掘组件(如标记化和命名实体识别(使用最大熵马尔可夫模型(MEMM)和基于模式识别的分类器)之间的关系。结果表明,对于化学,特别是消除标记化技术产生的噪声会导致命名实体识别(NER)准确性略高于其他方法。较差的标记化会转化为分类器组件较差的输入,这反过来又会导致 I 型或 II 型错误增加,从而降低整体性能。在 Sciborg 语料库上,使用新标记器同时保留相同的 MEMM 组件的基于工作流程的系统,将 F 分数从 82.35%提高到 84.44%。在 PubMed 语料库上,它记录的 F 分数为 84.84%,而 OSCAR 为 84.23%。