National Centre for Text Mining and School of Computer Science, University of Manchester, 131 Princess Street, Manchester, M1 7DN, UK.
Database (Oxford). 2012 Mar 20;2012:bas010. doi: 10.1093/database/bas010. Print 2012.
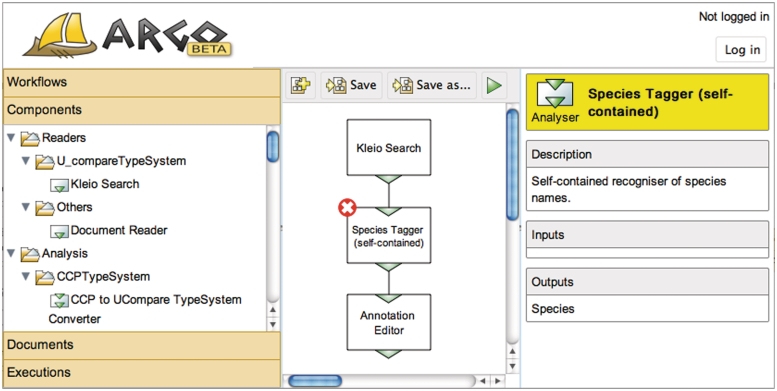
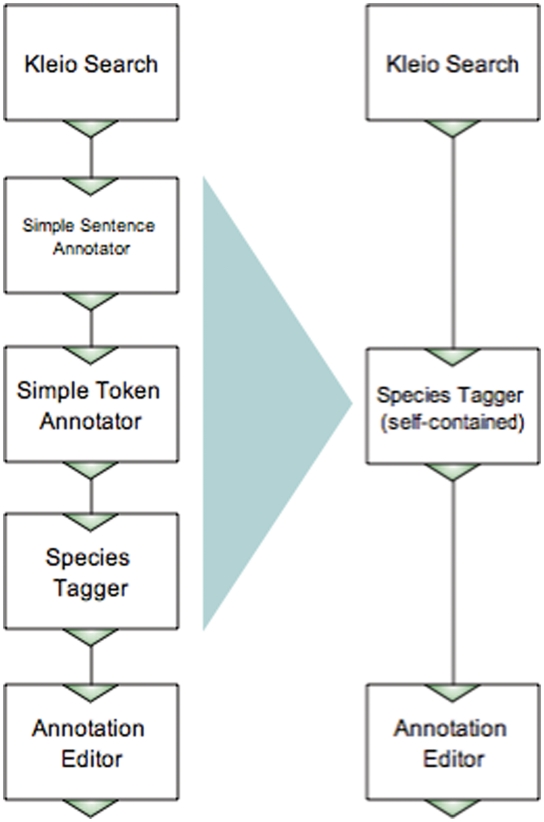
Curation of biomedical literature is often supported by the automatic analysis of textual content that generally involves a sequence of individual processing components. Text mining (TM) has been used to enhance the process of manual biocuration, but has been focused on specific databases and tasks rather than an environment integrating TM tools into the curation pipeline, catering for a variety of tasks, types of information and applications. Processing components usually come from different sources and often lack interoperability. The well established Unstructured Information Management Architecture is a framework that addresses interoperability by defining common data structures and interfaces. However, most of the efforts are targeted towards software developers and are not suitable for curators, or are otherwise inconvenient to use on a higher level of abstraction. To overcome these issues we introduce Argo, an interoperable, integrative, interactive and collaborative system for text analysis with a convenient graphic user interface to ease the development of processing workflows and boost productivity in labour-intensive manual curation. Robust, scalable text analytics follow a modular approach, adopting component modules for distinct levels of text analysis. The user interface is available entirely through a web browser that saves the user from going through often complicated and platform-dependent installation procedures. Argo comes with a predefined set of processing components commonly used in text analysis, while giving the users the ability to deposit their own components. The system accommodates various areas and levels of user expertise, from TM and computational linguistics to ontology-based curation. One of the key functionalities of Argo is its ability to seamlessly incorporate user-interactive components, such as manual annotation editors, into otherwise completely automatic pipelines. As a use case, we demonstrate the functionality of an in-built manual annotation editor that is well suited for in-text corpus annotation tasks. DATABASE URL: http://www.nactem.ac.uk/Argo.
生物医学文献的编纂通常需要借助对文本内容的自动分析来完成,而这通常涉及一系列单独的处理组件。文本挖掘 (TM) 已被用于增强手动生物编纂的过程,但它主要集中在特定的数据库和任务上,而不是在一个集成 TM 工具的编纂流程的环境中,以满足各种任务、信息类型和应用的需求。处理组件通常来自不同的来源,并且往往缺乏互操作性。成熟的非结构化信息管理架构 (Unstructured Information Management Architecture) 是一个通过定义通用数据结构和接口来解决互操作性问题的框架。然而,大多数努力都针对软件开发人员,而不适合编纂人员,或者在更高的抽象层次上使用起来很不方便。为了解决这些问题,我们引入了 Argo,这是一个用于文本分析的可互操作、集成、交互和协作的系统,它具有方便的图形用户界面,可以简化处理工作流程的开发,并在劳动密集型的手动编纂中提高生产力。稳健、可扩展的文本分析采用模块化方法,采用组件模块来进行不同层次的文本分析。用户界面完全可以通过网络浏览器使用,用户无需经历通常复杂且依赖于平台的安装过程。Argo 提供了一组常用的处理组件,同时允许用户存储自己的组件。该系统可以适应各种领域和用户专业水平,从 TM 和计算语言学到基于本体的编纂。Argo 的一个关键功能是能够将用户交互组件(例如手动注释编辑器)无缝地集成到其他完全自动化的管道中。作为一个用例,我们展示了内置手动注释编辑器的功能,它非常适合用于文本内语料库注释任务。数据库 URL:http://www.nactem.ac.uk/Argo。