Fukuchi Satoshi, Hosoda Kazuo, Homma Keiichi, Gojobori Takashi, Nishikawa Ken
Center for Information Biology & DNA Data Bank of Japan, National Institute of Genetics, Yata 1111, Mishima, Shizuoka 411-8540, Japan.
BMC Struct Biol. 2011 Jun 22;11:29. doi: 10.1186/1472-6807-11-29.
Although structural domains in proteins (SDs) are important, half of the regions in the human proteome are currently left with no SD assignments. These unassigned regions consist not only of novel SDs, but also of intrinsically disordered (ID) regions since proteins, especially those in eukaryotes, generally contain a significant fraction of ID regions. As ID regions can be inferred from amino acid sequences, a method that combines SD and ID region assignments can determine the fractions of SDs and ID regions in any proteome.
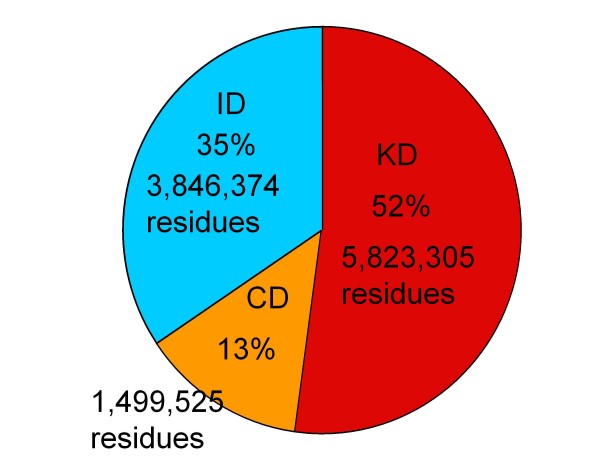
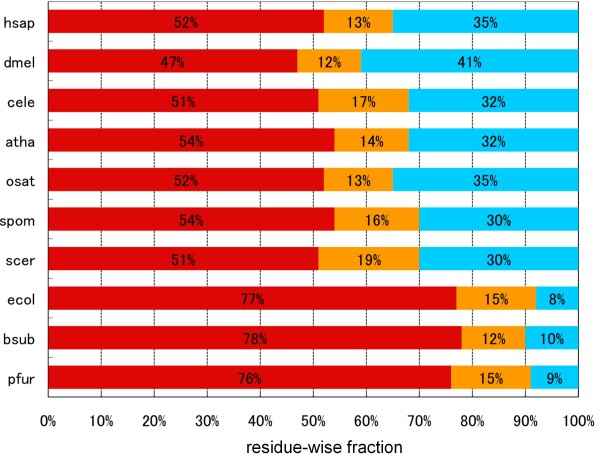
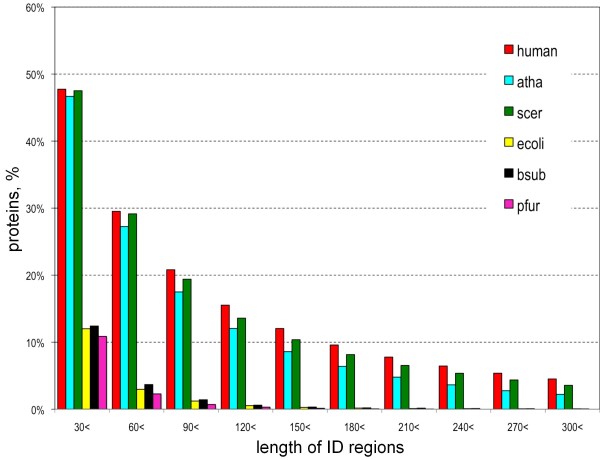
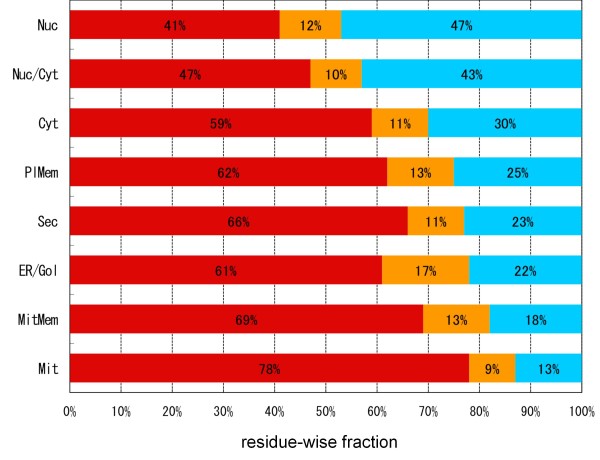
In contrast to other available ID prediction programs that merely identify likely ID regions, the DICHOT system we previously developed classifies the entire protein sequence into SDs and ID regions. Application of DICHOT to the human proteome revealed that residue-wise ID regions constitute 35%, SDs with similarity to PDB structures comprise 52%, while SDs with no similarity to PDB structures account for the remaining 13%. The last group consists of novel structural domains, termed cryptic domains, which serve as good targets of structural genomics. The DICHOT method applied to the proteomes of other model organisms indicated that eukaryotes generally have high ID contents, while prokaryotes do not. In human proteins, ID contents differ among subcellular localizations: nuclear proteins had the highest residue-wise ID fraction (47%), while mitochondrial proteins exhibited the lowest (13%). Phosphorylation and O-linked glycosylation sites were found to be located preferentially in ID regions. As O-linked glycans are attached to residues in the extracellular regions of proteins, the modification is likely to protect the ID regions from proteolytic cleavage in the extracellular environment. Alternative splicing events tend to occur more frequently in ID regions. We interpret this as evidence that natural selection is operating at the protein level in alternative splicing.
We classified entire regions of proteins into the two categories, SDs and ID regions and thereby obtained various kinds of complete genome-wide statistics. The results of the present study are important basic information for understanding protein structural architectures and have been made publicly available at http://spock.genes.nig.ac.jp/~genome/DICHOT.
尽管蛋白质中的结构域很重要,但目前人类蛋白质组中有一半区域尚无结构域归属。这些未归属区域不仅包含新的结构域,还包括内在无序区域,因为蛋白质,尤其是真核生物中的蛋白质,通常含有相当比例的内在无序区域。由于可以从氨基酸序列推断出内在无序区域,一种结合结构域和内在无序区域归属的方法能够确定任何蛋白质组中结构域和内在无序区域的比例。
与其他仅识别可能的内在无序区域的现有内在无序预测程序不同,我们之前开发的DICHOT系统将整个蛋白质序列分类为结构域和内在无序区域。将DICHOT应用于人类蛋白质组发现,逐残基的内在无序区域占35%,与蛋白质数据银行(PDB)结构相似的结构域占52%,而与PDB结构无相似性的结构域占其余的13%。最后一组包括新的结构域,称为隐秘结构域,它们是结构基因组学的良好目标。将DICHOT方法应用于其他模式生物的蛋白质组表明,真核生物通常具有较高的内在无序含量,而原核生物则不然。在人类蛋白质中,内在无序含量在亚细胞定位之间存在差异:核蛋白的逐残基内在无序比例最高(47%),而线粒体蛋白的比例最低(13%)。发现磷酸化和O-连接糖基化位点优先位于内在无序区域。由于O-连接聚糖附着在蛋白质细胞外区域的残基上,这种修饰可能保护内在无序区域在细胞外环境中不被蛋白水解切割。可变剪接事件往往更频繁地发生在内在无序区域。我们将此解释为自然选择在可变剪接的蛋白质水平上起作用的证据。
我们将蛋白质的整个区域分为结构域和内在无序区域两类,从而获得了各种全基因组的完整统计数据。本研究结果是理解蛋白质结构架构的重要基础信息,已在http://spock.genes.nig.ac.jp/~genome/DICHOT上公开提供。