Department of Chemistry and Biomolecular Sciences and ARC Centre of Excellence in Bioinformatics, Macquarie University, Sydney, Australia.
J Cheminform. 2011 Aug 8;3:30. doi: 10.1186/1758-2946-3-30.
The recent public availability of the human metabolome and natural product datasets has revitalized "metabolite-likeness" and "natural product-likeness" as a drug design concept to design lead libraries targeting specific pathways. Many reports have analyzed the physicochemical property space of biologically important datasets, with only a few comprehensively characterizing the scaffold diversity in public datasets of biological interest. With large collections of high quality public data currently available, we carried out a comparative analysis of current day leads with other biologically relevant datasets.
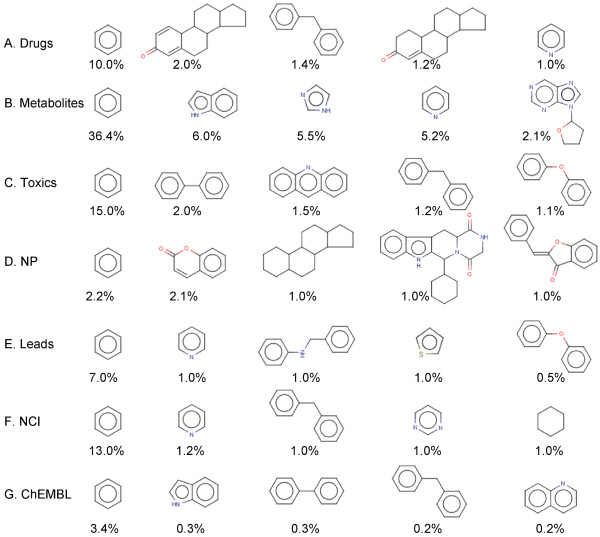
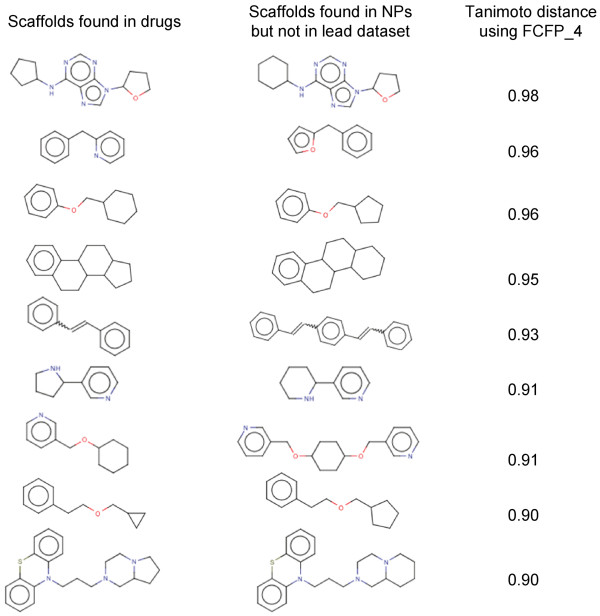
In this study, we note a two-fold enrichment of metabolite scaffolds in drug dataset (42%) as compared to currently used lead libraries (23%). We also note that only a small percentage (5%) of natural product scaffolds space is shared by the lead dataset. We have identified specific scaffolds that are present in metabolites and natural products, with close counterparts in the drugs, but are missing in the lead dataset. To determine the distribution of compounds in physicochemical property space we analyzed the molecular polar surface area, the molecular solubility, the number of rings and the number of rotatable bonds in addition to four well-known Lipinski properties. Here, we note that, with only few exceptions, most of the drugs follow Lipinski's rule. The average values of the molecular polar surface area and the molecular solubility in metabolites is the highest while the number of rings is the lowest. In addition, we note that natural products contain the maximum number of rings and the rotatable bonds than any other dataset under consideration.
Currently used lead libraries make little use of the metabolites and natural products scaffold space. We believe that metabolites and natural products are recognized by at least one protein in the biosphere therefore, sampling the fragment and scaffold space of these compounds, along with the knowledge of distribution in physicochemical property space, can result in better lead libraries. Hence, we recommend the greater use of metabolites and natural products while designing lead libraries. Nevertheless, metabolites have a limited distribution in chemical space that limits the usage of metabolites in library design.
人类代谢组和天然产物数据集的最近公开可用性使“代谢物样”和“天然产物样”重新成为一种药物设计概念,用于设计针对特定途径的先导化合物库。许多报告分析了生物重要数据集的物理化学性质空间,只有少数报告全面描述了生物相关公共数据集中的支架多样性。目前有大量高质量的公共数据集合,我们对现有先导化合物与其他生物相关数据集进行了比较分析。
在这项研究中,我们注意到药物数据集中代谢物支架的含量增加了两倍(42%),而目前使用的先导化合物库中则为 23%。我们还注意到,天然产物支架空间中只有一小部分(5%)与先导化合物库共享。我们已经确定了存在于代谢物和天然产物中的特定支架,它们在药物中有密切的对应物,但在先导化合物库中却没有。为了确定化合物在物理化学性质空间中的分布,我们分析了分子极性表面积、分子溶解度、环数和可旋转键数,以及四个著名的 Lipinski 性质。在这里,我们注意到,除了少数例外,大多数药物都遵循 Lipinski 规则。代谢物的分子极性表面积和分子溶解度平均值最高,而环数最低。此外,我们注意到天然产物比任何其他考虑的数据集都包含最多的环数和可旋转键数。
目前使用的先导化合物库很少利用代谢物和天然产物的支架空间。我们认为,代谢物和天然产物至少被生物圈中的一种蛋白质识别,因此,从这些化合物的片段和支架空间采样,以及了解其在物理化学性质空间中的分布,可以产生更好的先导化合物库。因此,我们建议在设计先导化合物库时更多地利用代谢物和天然产物。然而,代谢物在化学空间中的分布有限,限制了其在文库设计中的应用。