Stobbe Miranda D, Houten Sander M, Jansen Gerbert A, van Kampen Antoine H C, Moerland Perry D
Bioinformatics Laboratory, Academic Medical Center, University of Amsterdam, PO Box 22700, 1100 DE, Amsterdam, the Netherlands.
BMC Syst Biol. 2011 Oct 14;5:165. doi: 10.1186/1752-0509-5-165.
Multiple pathway databases are available that describe the human metabolic network and have proven their usefulness in many applications, ranging from the analysis and interpretation of high-throughput data to their use as a reference repository. However, so far the various human metabolic networks described by these databases have not been systematically compared and contrasted, nor has the extent to which they differ been quantified. For a researcher using these databases for particular analyses of human metabolism, it is crucial to know the extent of the differences in content and their underlying causes. Moreover, the outcomes of such a comparison are important for ongoing integration efforts.
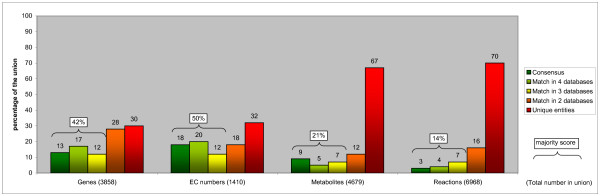
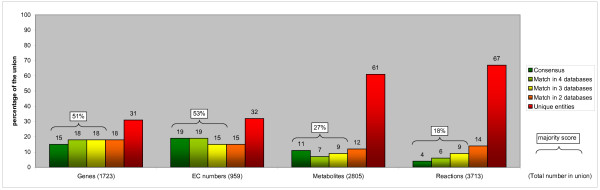
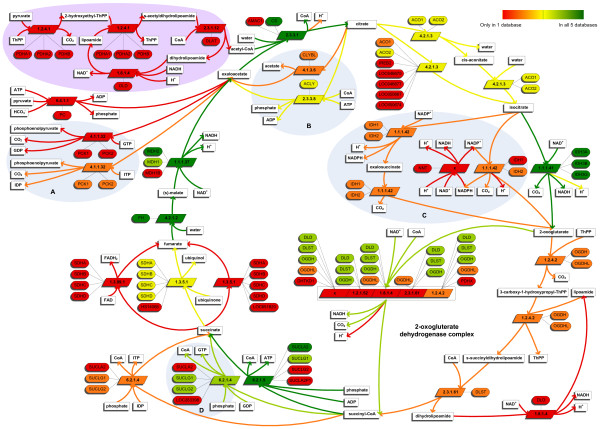
We compared the genes, EC numbers and reactions of five frequently used human metabolic pathway databases. The overlap is surprisingly low, especially on reaction level, where the databases agree on 3% of the 6968 reactions they have combined. Even for the well-established tricarboxylic acid cycle the databases agree on only 5 out of the 30 reactions in total. We identified the main causes for the lack of overlap. Importantly, the databases are partly complementary. Other explanations include the number of steps a conversion is described in and the number of possible alternative substrates listed. Missing metabolite identifiers and ambiguous names for metabolites also affect the comparison.
Our results show that each of the five networks compared provides us with a valuable piece of the puzzle of the complete reconstruction of the human metabolic network. To enable integration of the networks, next to a need for standardizing the metabolite names and identifiers, the conceptual differences between the databases should be resolved. Considerable manual intervention is required to reach the ultimate goal of a unified and biologically accurate model for studying the systems biology of human metabolism. Our comparison provides a stepping stone for such an endeavor.
现有多个描述人类代谢网络的通路数据库,且已在许多应用中证明了其有用性,范围从高通量数据的分析与解释到用作参考知识库。然而,迄今为止,这些数据库所描述的各种人类代谢网络尚未得到系统的比较和对比,它们之间的差异程度也未被量化。对于使用这些数据库进行人类代谢特定分析的研究人员而言,了解内容差异的程度及其潜在原因至关重要。此外,这种比较的结果对于正在进行的整合工作也很重要。
我们比较了五个常用的人类代谢通路数据库的基因、酶委员会编号(EC编号)和反应。重叠程度惊人地低,尤其是在反应层面,这些数据库在它们合并的6968个反应中仅有3%是一致的。即使对于成熟的三羧酸循环,这些数据库在总共30个反应中也仅在5个反应上达成一致。我们确定了缺乏重叠的主要原因。重要的是,这些数据库部分是互补的。其他解释包括描述一个转化过程的步骤数量以及列出的可能替代底物的数量。缺失的代谢物标识符和代谢物的模糊名称也影响了比较。
我们的结果表明,所比较的五个网络中的每一个都为我们提供了人类代谢网络完整重建难题中的一块有价值的拼图。为了实现网络的整合,除了需要标准化代谢物名称和标识符之外,还应解决数据库之间的概念差异。需要大量的人工干预才能实现用于研究人类代谢系统生物学的统一且生物学准确的模型这一最终目标。我们的比较为此类努力提供了一块垫脚石。