Section of Bioinformatics, Division of Systems Medicine, Department of Metabolism, Digestion, and Reproduction, Faculty of Medicine, Imperial College London, London, United Kingdom.
Toxalim (Research Centre in Food Toxicology), Université de Toulouse, INRAE, ENVT, INP-Purpan, UPS, Toulouse, France.
PLoS Comput Biol. 2021 Sep 7;17(9):e1009105. doi: 10.1371/journal.pcbi.1009105. eCollection 2021 Sep.
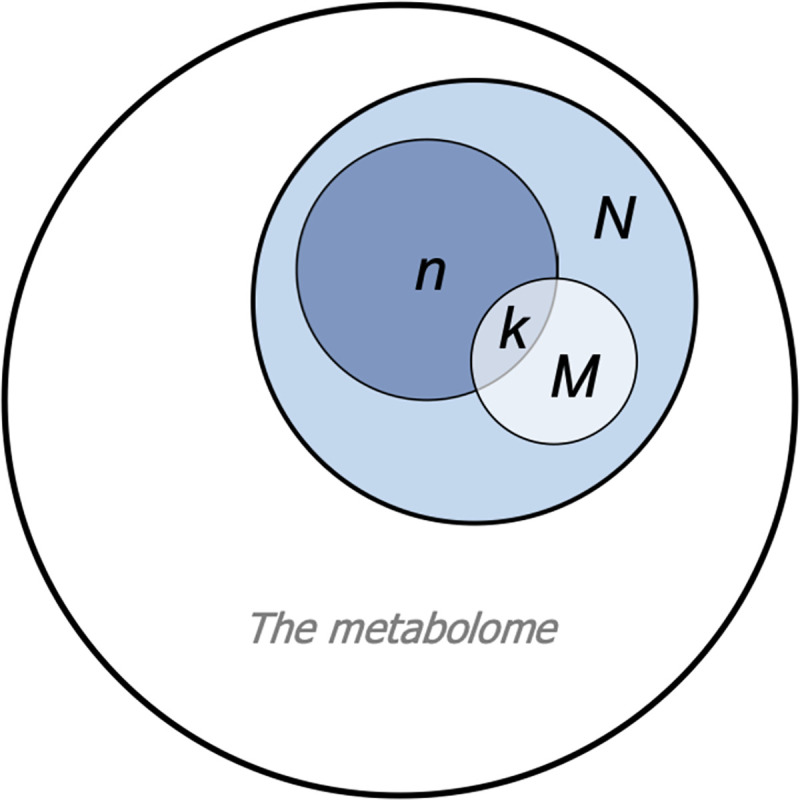
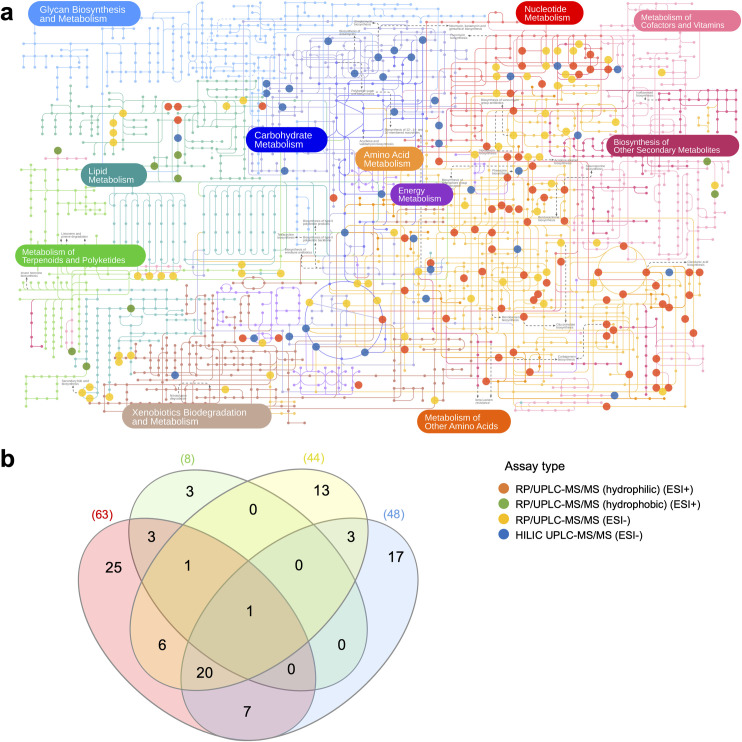
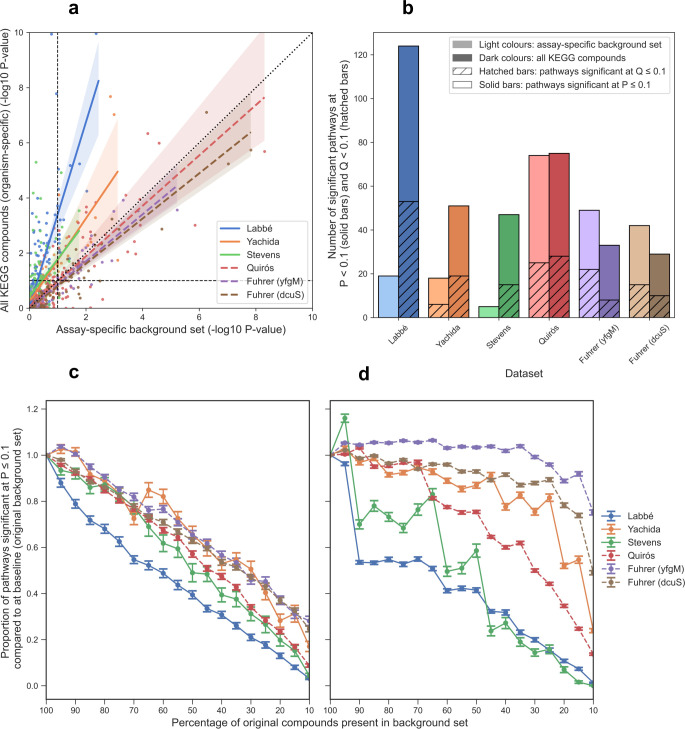
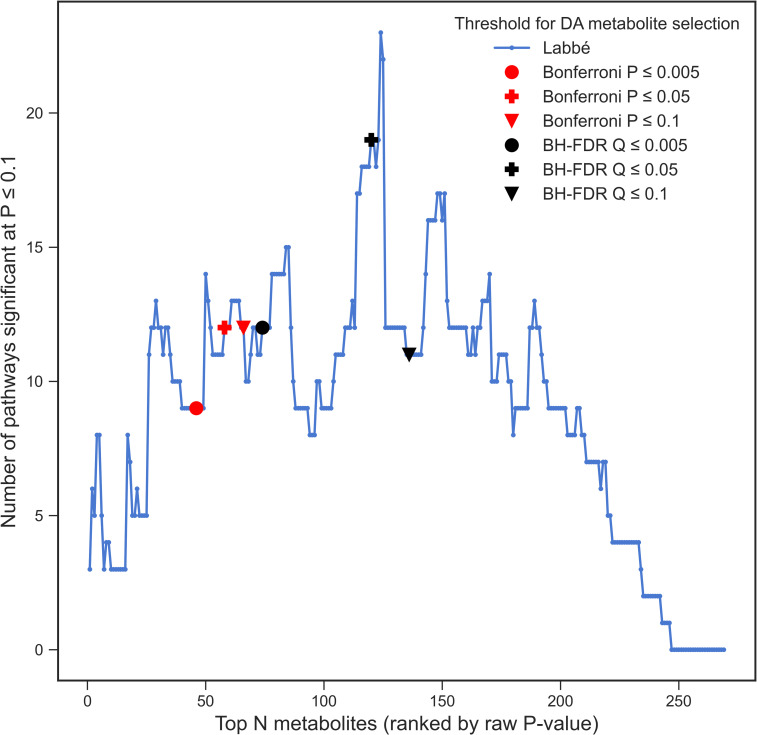
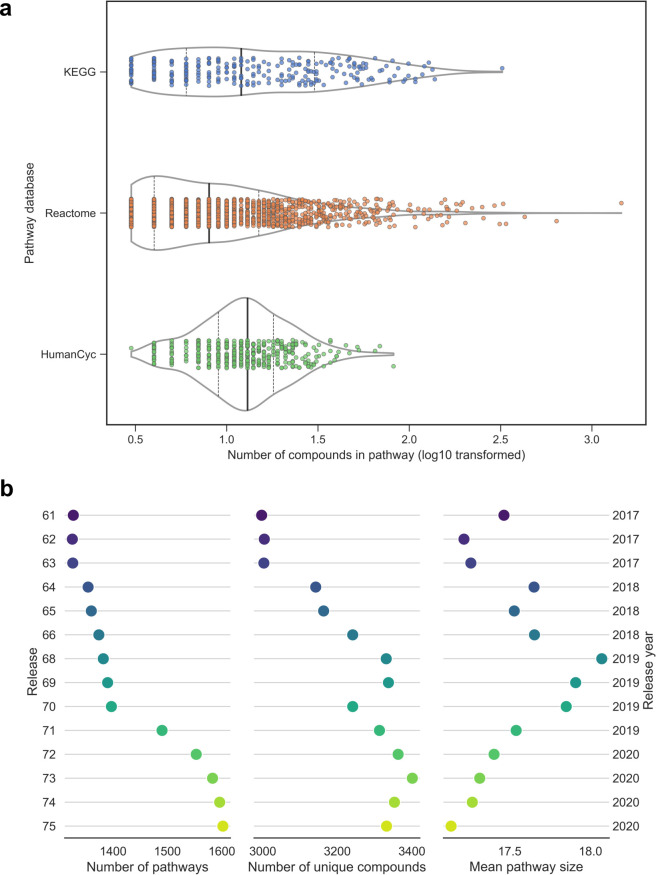
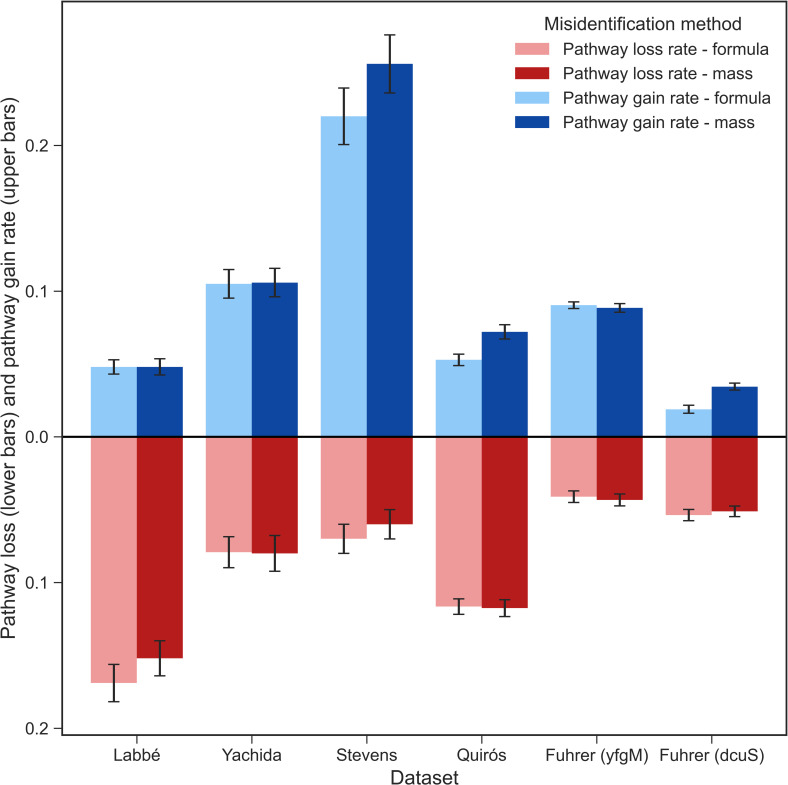
Over-representation analysis (ORA) is one of the commonest pathway analysis approaches used for the functional interpretation of metabolomics datasets. Despite the widespread use of ORA in metabolomics, the community lacks guidelines detailing its best-practice use. Many factors have a pronounced impact on the results, but to date their effects have received little systematic attention. Using five publicly available datasets, we demonstrated that changes in parameters such as the background set, differential metabolite selection methods, and pathway database used can result in profoundly different ORA results. The use of a non-assay-specific background set, for example, resulted in large numbers of false-positive pathways. Pathway database choice, evaluated using three of the most popular metabolic pathway databases (KEGG, Reactome, and BioCyc), led to vastly different results in both the number and function of significantly enriched pathways. Factors that are specific to metabolomics data, such as the reliability of compound identification and the chemical bias of different analytical platforms also impacted ORA results. Simulated metabolite misidentification rates as low as 4% resulted in both gain of false-positive pathways and loss of truly significant pathways across all datasets. Our results have several practical implications for ORA users, as well as those using alternative pathway analysis methods. We offer a set of recommendations for the use of ORA in metabolomics, alongside a set of minimal reporting guidelines, as a first step towards the standardisation of pathway analysis in metabolomics.
过度代表分析(ORA)是用于代谢组学数据集功能解释的最常用途径分析方法之一。尽管 ORA 在代谢组学中被广泛使用,但该领域缺乏详细说明最佳实践使用方法的指南。许多因素对结果有显著影响,但迄今为止,它们的影响尚未得到系统关注。使用五个公开可用的数据集,我们证明了参数(如背景集、差异代谢物选择方法和使用的途径数据库)的变化会导致 ORA 结果发生深刻变化。例如,使用非特定于测定的背景集,会导致大量错误的阳性途径。使用三种最受欢迎的代谢途径数据库(KEGG、Reactome 和 BioCyc)评估途径数据库选择,导致显著富集途径的数量和功能都有很大差异。代谢组学数据特有的因素,如化合物鉴定的可靠性和不同分析平台的化学偏倚,也会影响 ORA 结果。即使化合物错误识别率低至 4%,也会导致所有数据集的假阳性途径增加和真正显著途径丢失。我们的结果对 ORA 用户以及使用替代途径分析方法的用户具有实际意义。我们提供了一套在代谢组学中使用 ORA 的建议,并制定了一套最低报告指南,作为代谢组学中途径分析标准化的第一步。