Institute for Theoretical Physics, KULeuven, Celestijnenlaan 200D, B-3001 Leuven, Belgium.
BMC Bioinformatics. 2011 Dec 2;12:464. doi: 10.1186/1471-2105-12-464.
Several preprocessing methods are available for the analysis of Affymetrix Genechips arrays. The most popular algorithms analyze the measured fluorescence intensities with statistical methods. Here we focus on a novel algorithm, AffyILM, available from Bioconductor, which relies on inputs from hybridization thermodynamics and uses an extended Langmuir isotherm model to compute transcript concentrations. These concentrations are then employed in the statistical analysis. We compared the performance of AffyILM and other traditional methods both in the old and in the newest generation of GeneChips.
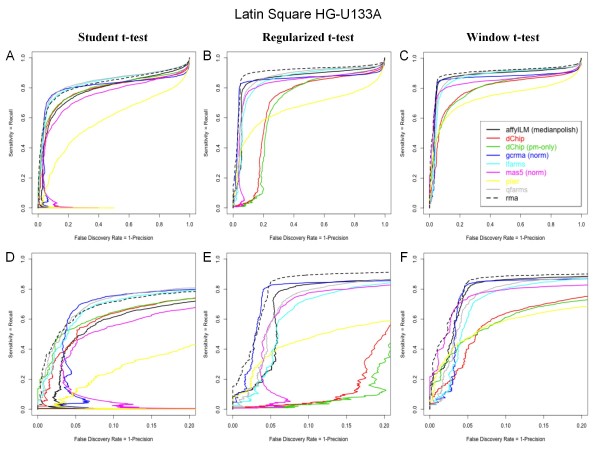
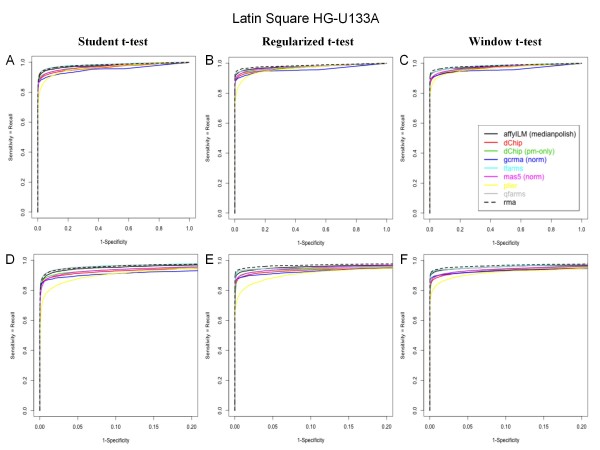
Tissue mixture and Latin Square datasets (provided by Affymetrix) were used to assess the performances of the differential expression analysis depending on the preprocessing strategy. A correlation analysis conducted on the tissue mixture data reveals that the median-polish algorithm allows to best summarize AffyILM concentrations computed at the probe-level. Those correlation results are equivalent to the best correlations observed using popular preprocessing methods relying on intensity values. The performances of each tested preprocessing algorithm were quantified using the Latin Square HG-U133A dataset, thanks to the comparison of differential analysis results with the list of spiked genes. The figures of merit generated illustrates that the performances associated to AffyILM(medianpolish), inferred from the present statistical analysis, are comparable to the best performing strategies previously reported.
Converting probe intensities to estimates of target concentrations prior to the statistical analysis, AffyILM(medianpolish) is one of the best performing strategy currently available. Using hybridization theory, probe-level estimates of target concentrations should be identically distributed. In the future, a probe-level multivariate analysis of the concentrations should be compared to the univariate analysis of probe-set summarized expression data.
有几种预处理方法可用于分析 Affymetrix Genechips 阵列。最流行的算法是用统计方法分析测量的荧光强度。在这里,我们关注一种新的算法,即 Bioconductor 提供的 AffyILM,它依赖于杂交热力学的输入,并使用扩展的朗缪尔等温模型来计算转录物浓度。然后,这些浓度被用于统计分析。我们比较了 AffyILM 和其他传统方法在旧一代和最新一代 GeneChips 中的性能。
使用组织混合物和拉丁方数据集(由 Affymetrix 提供)来评估根据预处理策略的差异表达分析的性能。对组织混合物数据进行的相关分析表明,中值-抛光算法允许最好地总结在探针水平计算的 AffyILM 浓度。这些相关结果与使用基于强度值的流行预处理方法观察到的最佳相关结果相当。使用拉丁方 HG-U133A 数据集,通过比较差异分析结果与添加基因列表,对每种测试的预处理算法的性能进行了量化。生成的质量度量值表明,从本统计分析推断的 AffyILM(中值-抛光)的性能与之前报道的最佳性能策略相当。
在进行统计分析之前,将探针强度转换为目标浓度的估计值,AffyILM(中值-抛光)是目前可用的性能最佳的策略之一。使用杂交理论,目标浓度的探针级估计值应该是相同分布的。在未来,应该对浓度的探针级多元分析与探针集汇总表达数据的单变量分析进行比较。