Department of EECS, The University of Kansas, Lawrence, Kansas, USA.
BMC Bioinformatics. 2011 Nov 24;12 Suppl 12(Suppl 12):S7. doi: 10.1186/1471-2105-12-S12-S7.
Along with the rapid digitalization of health data (e.g. Electronic Health Records), there is an increasing concern on maintaining data privacy while garnering the benefits, especially when the data are required to be published for secondary use. Most of the current research on protecting health data privacy is centered around data de-identification and data anonymization, which removes the identifiable information from the published health data to prevent an adversary from reasoning about the privacy of the patients. However, published health data is not the only source that the adversaries can count on: with a large amount of information that people voluntarily share on the Web, sophisticated attacks that join disparate information pieces from multiple sources against health data privacy become practical. Limited efforts have been devoted to studying these attacks yet.
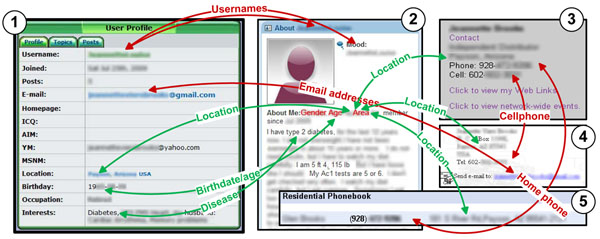
We study how patient privacy could be compromised with the help of today's information technologies. In particular, we show that private healthcare information could be collected by aggregating and associating disparate pieces of information from multiple online data sources including online social networks, public records and search engine results. We demonstrate a real-world case study to show user identity and privacy are highly vulnerable to the attribution, inference and aggregation attacks. We also show that people are highly identifiable to adversaries even with inaccurate information pieces about the target, with real data analysis.
We claim that too much information has been made available electronic and available online that people are very vulnerable without effective privacy protection.
随着健康数据(如电子健康记录)的快速数字化,人们越来越关注在获取利益的同时维护数据隐私,特别是当数据需要发布以供二次使用时。目前大多数关于保护健康数据隐私的研究都集中在数据去识别和数据匿名化上,这些方法从发布的健康数据中删除可识别信息,以防止对手推断患者的隐私。然而,发布的健康数据并不是对手唯一可以依赖的信息源:随着人们在网络上自愿共享的大量信息,从多个来源整合和关联不同信息片段以攻击健康数据隐私的复杂攻击变得切实可行。目前,针对这些攻击的研究还很有限。
我们研究了在当今信息技术的帮助下,患者隐私可能会受到怎样的侵犯。具体来说,我们表明,通过从多个在线数据源(包括在线社交网络、公共记录和搜索引擎结果)聚合和关联不同的信息片段,可以收集私人医疗保健信息。我们展示了一个真实世界的案例研究,表明用户身份和隐私非常容易受到归因、推断和聚合攻击的影响。我们还表明,即使对手掌握的有关目标的信息片段不准确,人们也很容易被对手识别,这是基于真实数据分析的结果。
我们声称,太多的信息已经在电子设备和网络上可用,而在没有有效隐私保护的情况下,人们非常脆弱。