Department of Biomedical Informatics, School of Medicine, Vanderbilt University, Nashville, TN, USA.
PLoS One. 2013;8(2):e53875. doi: 10.1371/journal.pone.0053875. Epub 2013 Feb 6.
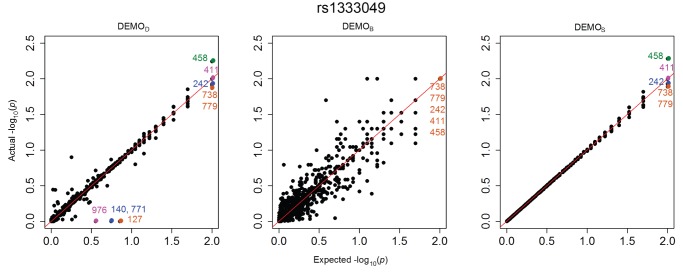
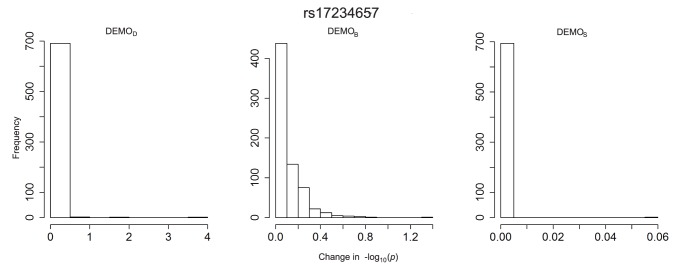
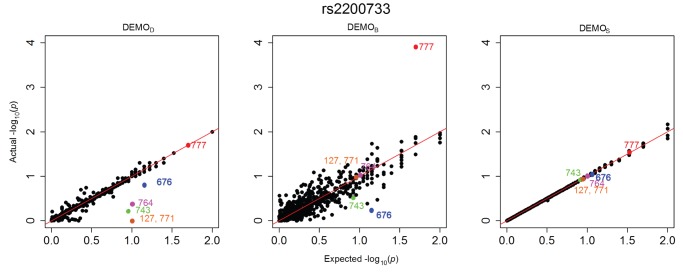
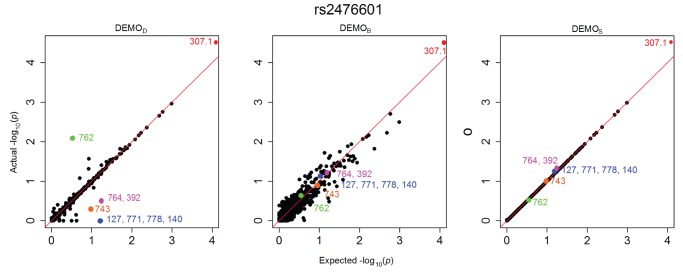
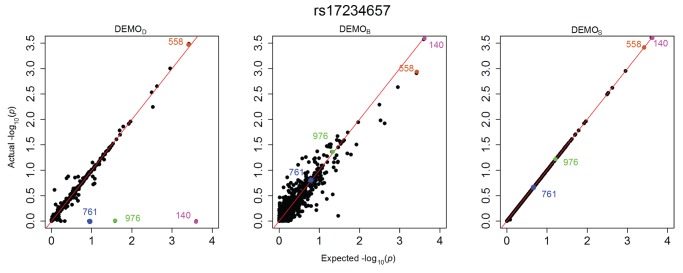
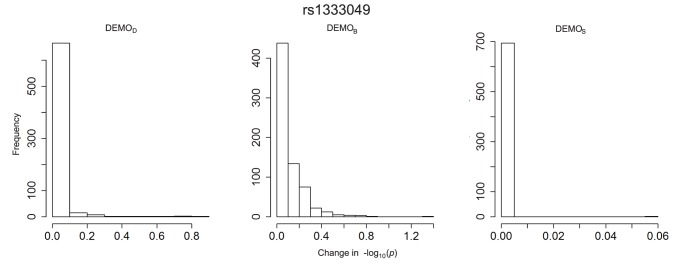
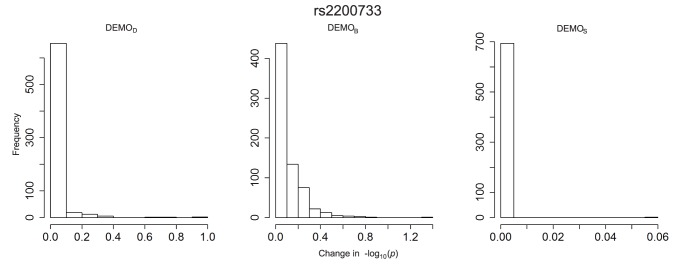
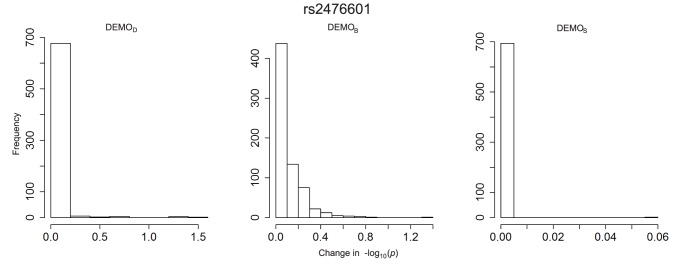
Health information technologies facilitate the collection of massive quantities of patient-level data. A growing body of research demonstrates that such information can support novel, large-scale biomedical investigations at a fraction of the cost of traditional prospective studies. While healthcare organizations are being encouraged to share these data in a de-identified form, there is hesitation over concerns that it will allow corresponding patients to be re-identified. Currently proposed technologies to anonymize clinical data may make unrealistic assumptions with respect to the capabilities of a recipient to ascertain a patients identity. We show that more pragmatic assumptions enable the design of anonymization algorithms that permit the dissemination of detailed clinical profiles with provable guarantees of protection. We demonstrate this strategy with a dataset of over one million medical records and show that 192 genotype-phenotype associations can be discovered with fidelity equivalent to non-anonymized clinical data.
健康信息技术促进了大量患者水平数据的收集。越来越多的研究表明,这种信息可以以传统前瞻性研究成本的一小部分支持新的、大规模的生物医学研究。虽然鼓励医疗保健组织以去识别的形式共享这些数据,但人们对数据可能会允许相应的患者被重新识别的担忧犹豫不决。目前提出的使临床数据匿名化的技术可能对接收者确定患者身份的能力做出不切实际的假设。我们表明,更务实的假设可以设计出匿名化算法,这些算法允许以可证明的保护保证来传播详细的临床概况。我们使用超过一百万个医疗记录的数据集证明了这一策略,并表明可以以与非匿名化临床数据相当的保真度发现 192 个基因型-表型关联。