Vitevitch Michael S, Ercal Gunes, Adagarla Bhargav
Department of Psychology, University of Kansas Lawrence, KS, USA.
Front Psychol. 2011 Dec 14;2:369. doi: 10.3389/fpsyg.2011.00369. eCollection 2011.
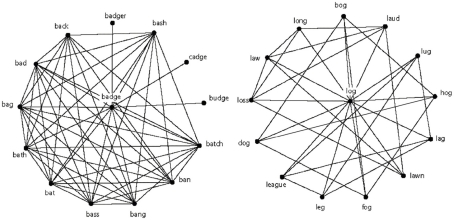
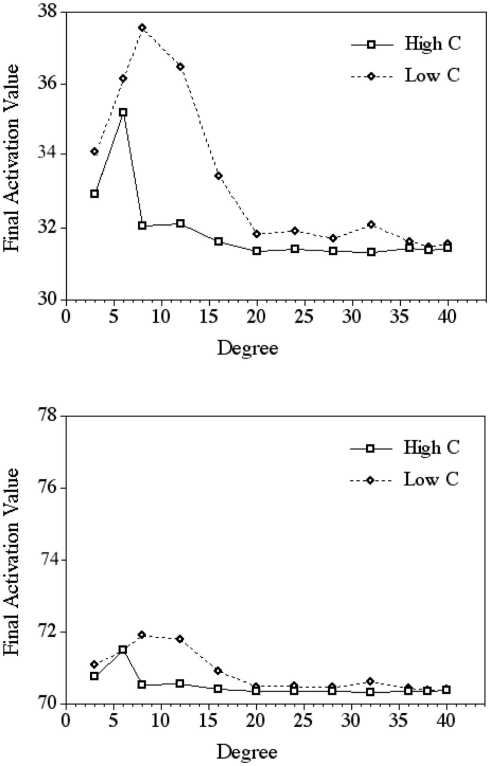
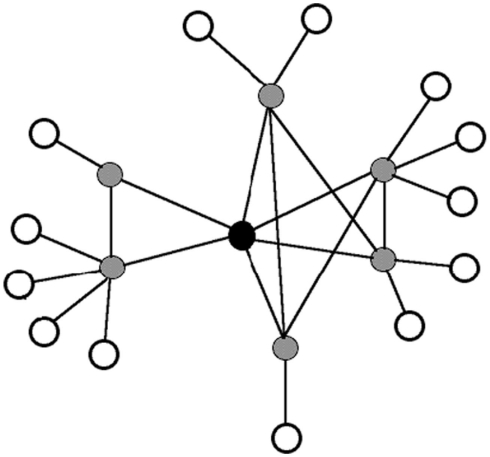
Network science describes how entities in complex systems interact, and argues that the structure of the network influences processing. Clustering coefficient, C - one measure of network structure - refers to the extent to which neighbors of a node are also neighbors of each other. Previous simulations suggest that networks with low C dissipate information (or disease) to a large portion of the network, whereas in networks with high C information (or disease) tends to be constrained to a smaller portion of the network (Newman, 2003). In the present simulation we examined how C influenced the spread of activation to a specific node, simulating retrieval of a specific lexical item in a phonological network. The results of the network simulation showed that words with lower C had higher activation values (indicating faster or more accurate retrieval from the lexicon) than words with higher C. These results suggest that a simple mechanism for lexical retrieval can account for the observations made in Chan and Vitevitch (2009), and have implications for diffusion dynamics in other fields.
网络科学描述了复杂系统中的实体如何相互作用,并认为网络结构会影响信息处理。聚类系数C(网络结构的一种度量)指的是一个节点的邻居彼此之间也是邻居的程度。先前的模拟表明,C值低的网络会将信息(或疾病)传播到网络的很大一部分,而在C值高的网络中,信息(或疾病)往往会被限制在网络的较小部分(纽曼,2003年)。在本模拟中,我们研究了C如何影响激活向特定节点的传播,模拟了语音网络中特定词汇项的检索。网络模拟结果表明,C值较低的单词比C值较高的单词具有更高的激活值(表明从词汇表中检索更快或更准确)。这些结果表明,一种简单的词汇检索机制可以解释陈和维特维奇(2009年)的观察结果,并对其他领域的扩散动力学具有启示意义。