Makowsky Robert, Beasley T Mark, Gadbury Gary L, Albert Jeffrey M, Kennedy Richard E, Allison David B
Department of Biostatistics, University of Alabama at Birmingham Birmingham, AL, USA.
Front Genet. 2011 Oct 31;2:75. doi: 10.3389/fgene.2011.00075. eCollection 2011.
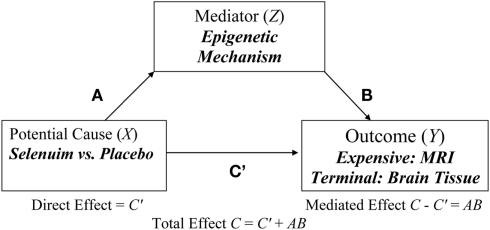
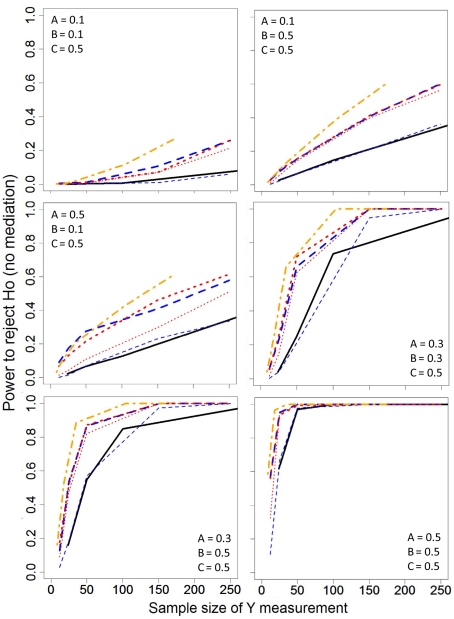
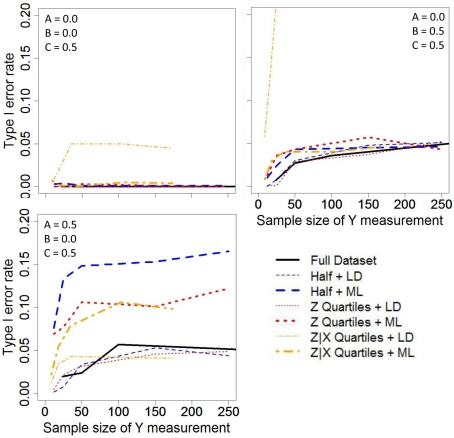
Several authors have acknowledged that testing mediational hypotheses between treatments, genes, physiological measures, and behaviors may substantially advance our understanding of how these associations operate. In psychiatric research, the costs of measuring the putative mediator or the outcome can be prohibitive. Extreme sampling designs have been validated as methods for reducing study costs by increasing power per subject measured on the more expensive variable when assessing bivariate relationships. However, there exist concerns about how missing data can potentially bias the results. Additionally, most mediation analysis techniques presuppose the joint measurement of mediators and outcomes for all subjects. There have been limited methodological developments for techniques that can evaluate putative mediators in studies that have employed extreme sampling, resulting in missing data. We demonstrate that extreme (selective) sampling strategies can be beneficial in the context of mediation analyses. Handling the missing data with maximum likelihood (ML) resulted in minimal power loss and unbiased parameter estimates. We must be cautious, though, in recommending the ML approach for extreme sampling designs because it yielded inflated Type 1 error rates under some null conditions. Yet, the use of extreme sampling designs and methods to handle the resultant missing data presents a viable research strategy.
几位作者已经承认,检验治疗、基因、生理指标和行为之间的中介假设可能会极大地推动我们对这些关联如何起作用的理解。在精神病学研究中,测量假定中介变量或结果的成本可能高得令人望而却步。极端抽样设计已被确认为一种方法,通过在评估双变量关系时提高对较昂贵变量进行测量的每个受试者的功效来降低研究成本。然而,人们担心缺失数据可能会如何潜在地使结果产生偏差。此外,大多数中介分析技术都预先假定对所有受试者的中介变量和结果进行联合测量。对于在采用极端抽样导致出现缺失数据的研究中评估假定中介变量的技术,方法学上的发展有限。我们证明,极端(选择性)抽样策略在中介分析的背景下可能是有益的。用最大似然法(ML)处理缺失数据导致的功效损失最小且参数估计无偏差。不过,在为极端抽样设计推荐ML方法时我们必须谨慎,因为在某些零假设条件下它会产生膨胀的第一类错误率。然而,使用极端抽样设计和方法来处理由此产生的缺失数据是一种可行的研究策略。