Udpa Nitin, Zhou Dan, Haddad Gabriel G, Bafna Vineet
Bioinformatics and Systems Biology Graduate Program, University of California San Diego La Jolla, CA, USA.
Front Genet. 2011 Nov 28;2:83. doi: 10.3389/fgene.2011.00083. eCollection 2011.
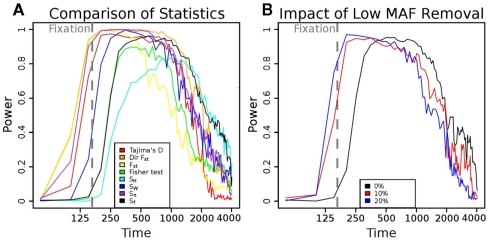
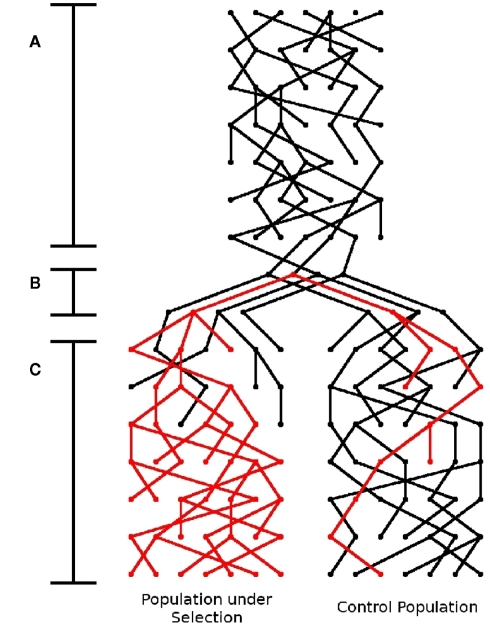
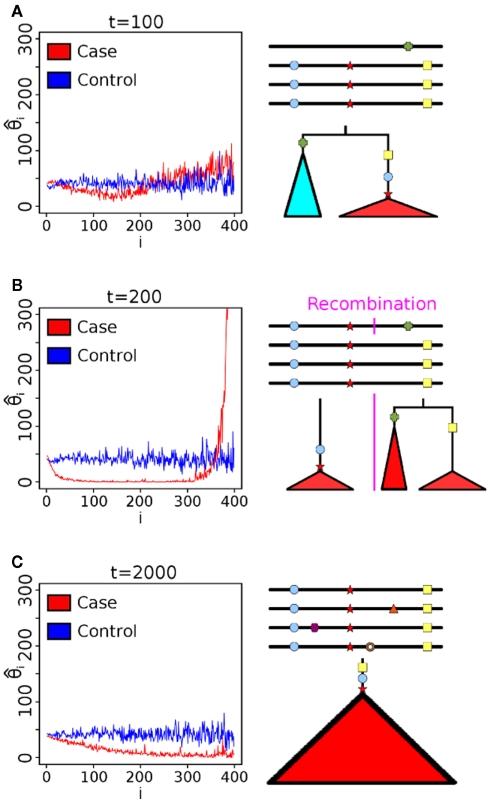
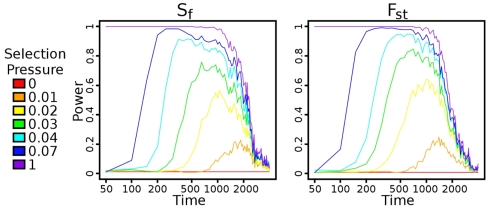
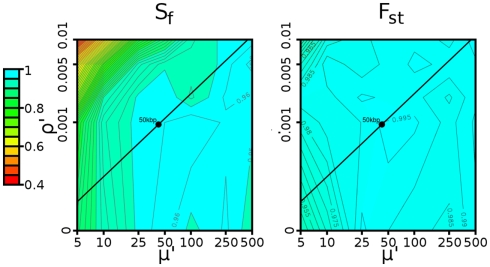
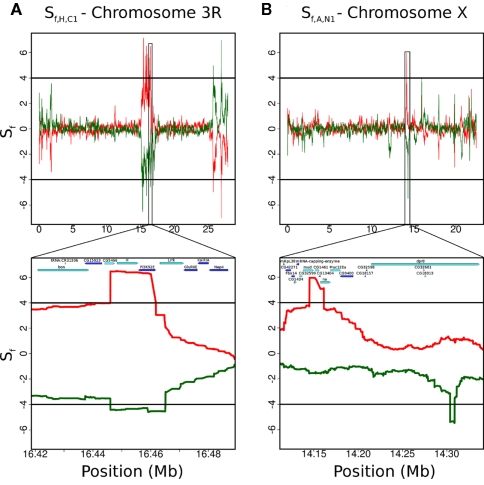
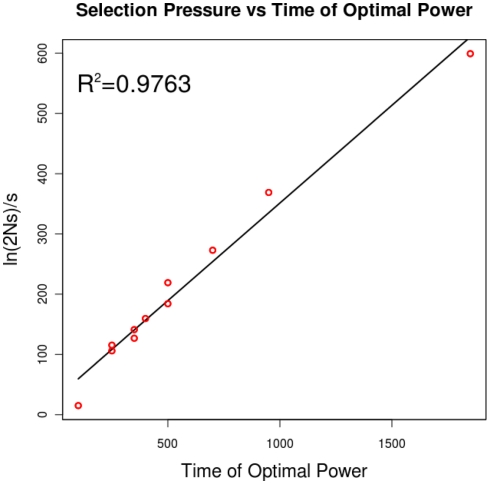
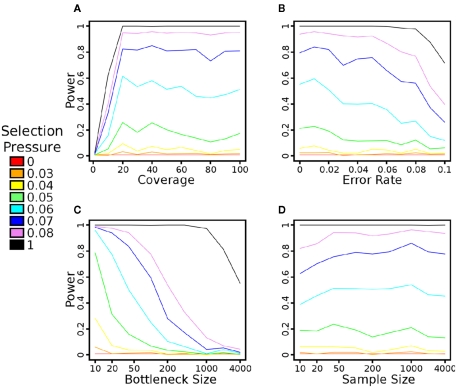
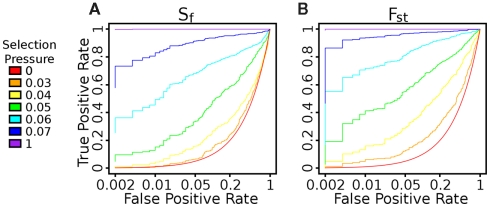
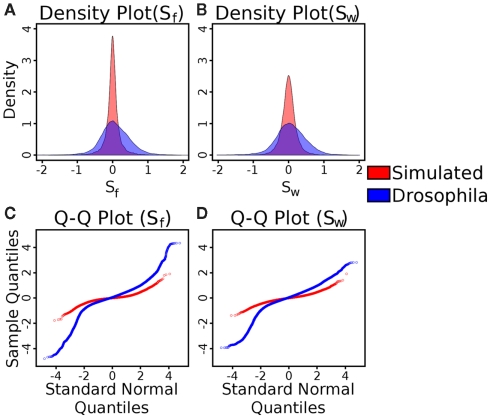
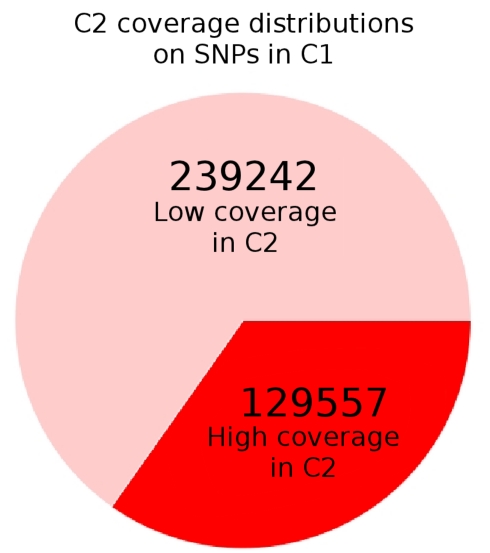
For smaller organisms with faster breeding cycles, artificial selection can be used to create sub-populations with different phenotypic traits. Genetic tests can be employed to identify the causal markers for the phenotypes, as a precursor to engineering strains with a combination of traits. Traditional approaches involve analyzing crosses of inbred strains to test for co-segregation with genetic markers. Here we take advantage of cheaper next generation sequencing techniques to identify genetic signatures of adaptation to the selection constraints. Obtaining individual sequencing data is often unrealistic due to cost and sample issues, so we focus on pooled genomic data. We explore a series of statistical tests for selection using pooled case (under selection) and control populations. The tests generally capture skews in the scaled frequency spectrum of alleles in a region, which are indicative of a selective sweep. Extensive simulations are used to show that these approaches work well for a wide range of population divergence times and strong selective pressures. Control vs control simulations are used to determine an empirical False Positive Rate, and regions under selection are determined using a 1% FPR level. We show that pooling does not have a significant impact on statistical power. The tests are also robust to reasonable variations in several different parameters, including window size, base-calling error rate, and sequencing coverage. We then demonstrate the viability (and the challenges) of one of these methods in two independent Drosophila populations (Drosophila melanogaster) bred under selection for hypoxia and accelerated development, respectively. Testing for extreme hypoxia tolerance showed clear signals of selection, pointing to loci that are important for hypoxia adaptation. Overall, we outline a strategy for finding regions under selection using pooled sequences, then devise optimal tests for that strategy. The approaches show promise for detecting selection, even several generations after fixation of the beneficial allele has occurred.
对于繁殖周期较短的较小生物体,可以利用人工选择来创建具有不同表型特征的亚种群。基因测试可用于识别表型的因果标记,作为构建具有多种性状组合的菌株的前奏。传统方法包括分析近交系的杂交以测试与遗传标记的共分离。在这里,我们利用更廉价的下一代测序技术来识别适应选择约束的遗传特征。由于成本和样本问题,获取个体测序数据通常不现实,因此我们专注于混合基因组数据。我们探索了一系列使用混合案例(处于选择状态)和对照种群进行选择的统计测试。这些测试通常会捕获一个区域中等位基因缩放频率谱中的偏差,这表明存在选择性清除。广泛的模拟表明,这些方法对于广泛的种群分化时间和强选择压力都能很好地发挥作用。使用对照与对照模拟来确定经验性假阳性率,并使用1%的错误发现率水平来确定选择区域。我们表明混合对统计功效没有显著影响。这些测试对于几个不同参数(包括窗口大小、碱基识别错误率和测序覆盖度)的合理变化也具有鲁棒性。然后,我们在分别为低氧和加速发育而培育的两个独立果蝇种群(黑腹果蝇)中证明了其中一种方法的可行性(以及挑战)。对极端低氧耐受性的测试显示出明显的选择信号,指向对低氧适应很重要的基因座。总体而言,我们概述了一种使用混合序列寻找选择区域的策略,然后为该策略设计了最优测试。这些方法对于检测选择显示出前景,即使在有益等位基因固定发生几代之后也是如此。