Department of Integrative Biology, University of California Berkeley, Berkeley, California, USA.
PLoS Genet. 2012 Feb;8(2):e1002469. doi: 10.1371/journal.pgen.1002469. Epub 2012 Feb 9.
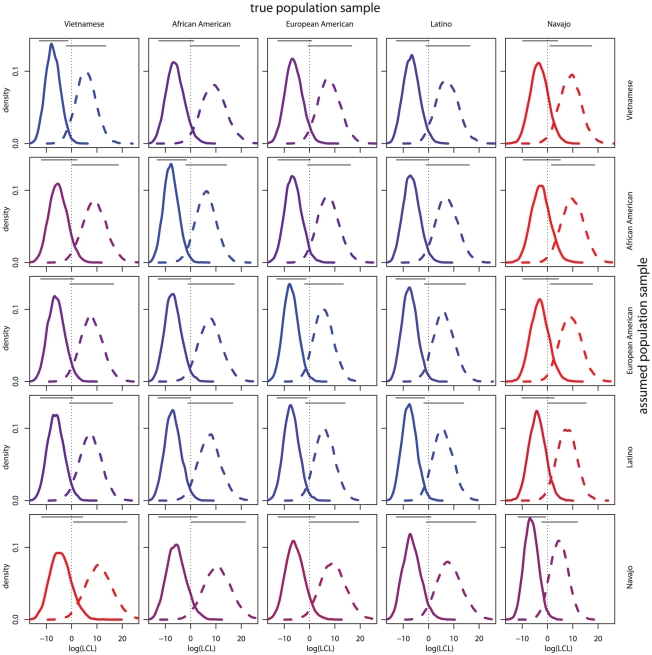
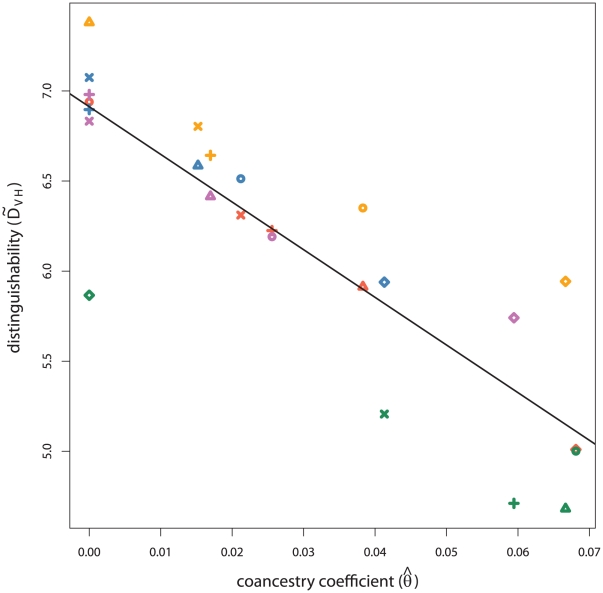
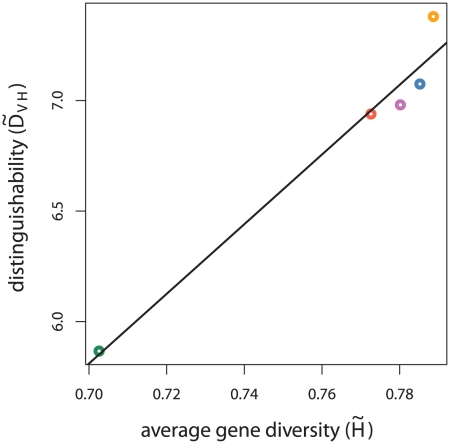
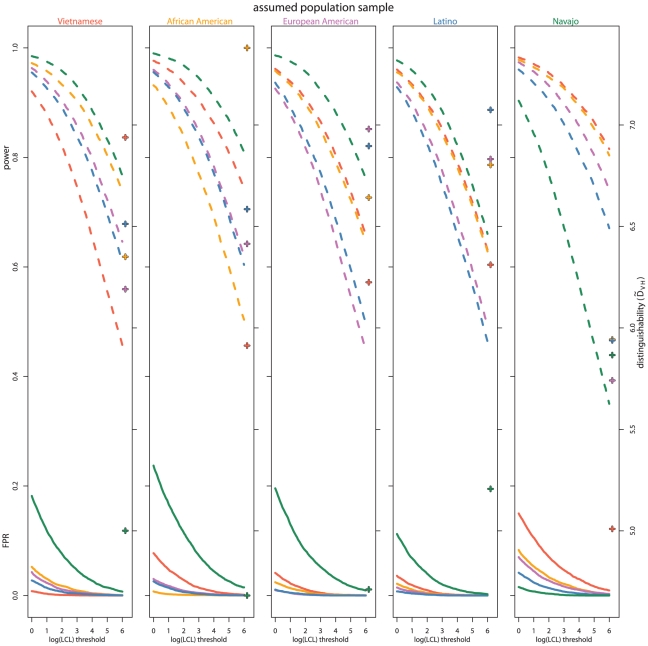
With the expansion of offender/arrestee DNA profile databases, genetic forensic identification has become commonplace in the United States criminal justice system. Implementation of familial searching has been proposed to extend forensic identification to family members of individuals with profiles in offender/arrestee DNA databases. In familial searching, a partial genetic profile match between a database entrant and a crime scene sample is used to implicate genetic relatives of the database entrant as potential sources of the crime scene sample. In addition to concerns regarding civil liberties, familial searching poses unanswered statistical questions. In this study, we define confidence intervals on estimated likelihood ratios for familial identification. Using these confidence intervals, we consider familial searching in a structured population. We show that relatives and unrelated individuals from population samples with lower gene diversity over the loci considered are less distinguishable. We also consider cases where the most appropriate population sample for individuals considered is unknown. We find that as a less appropriate population sample, and thus allele frequency distribution, is assumed, relatives and unrelated individuals become more difficult to distinguish. In addition, we show that relationship distinguishability increases with the number of markers considered, but decreases for more distant genetic familial relationships. All of these results indicate that caution is warranted in the application of familial searching in structured populations, such as in the United States.
随着犯罪嫌疑人/被捕者 DNA 图谱数据库的不断扩大,遗传法医鉴定在美国刑事司法系统中已变得非常普遍。有人提议实施家庭搜索,将法医鉴定扩展到犯罪嫌疑人/被捕者 DNA 数据库中个人的家庭成员。在家庭搜索中,数据库中个体的部分基因图谱与犯罪现场样本之间的匹配结果可用于暗示数据库中个体的遗传亲属是犯罪现场样本的潜在来源。除了对公民自由的关注外,家庭搜索还存在尚未解决的统计问题。在本研究中,我们定义了用于家族鉴定的估计似然比的置信区间。使用这些置信区间,我们考虑了在结构化人群中的家庭搜索。我们发现,在考虑的基因座上基因多样性较低的人群样本中,亲属和无关个体之间的区分度更低。我们还考虑了对于所考虑的个体来说,最合适的人群样本未知的情况。我们发现,随着假定的人群样本变得不那么合适,即等位基因频率分布发生变化,亲属和无关个体之间的区分变得更加困难。此外,我们还发现,随着所考虑的标记数量的增加,关系的可区分性会增加,但对于更远的遗传家族关系则会降低。所有这些结果都表明,在应用于结构化人群(例如美国)时,家庭搜索需要谨慎。