Wellcome Trust Sanger Institute, Wellcome Trust Genome Campus, Hinxton, CB10 1SA. UK.
Database (Oxford). 2012 Mar 20;2012:bas003. doi: 10.1093/database/bas003. Print 2012.
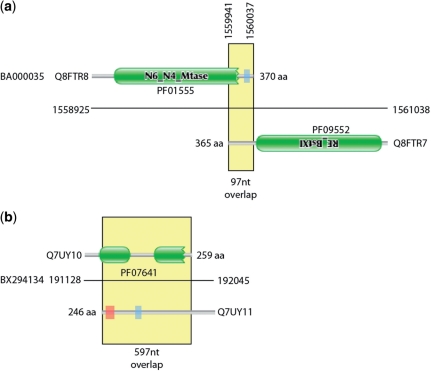
As the deluge of genomic DNA sequence grows the fraction of protein sequences that have been manually curated falls. In turn, as the number of laboratories with the ability to sequence genomes in a high-throughput manner grows, the informatics capability of those labs to accurately identify and annotate all genes within a genome may often be lacking. These issues have led to fears about transitive annotation errors making sequence databases less reliable. During the lifetime of the Pfam protein families database a number of protein families have been built, which were later identified as composed solely of spurious open reading frames (ORFs) either on the opposite strand or in a different, overlapping reading frame with respect to the true protein-coding or non-coding RNA gene. These families were deleted and are no longer available in Pfam. However, we realized that these may perform a useful function to identify new spurious ORFs. We have collected these families together in AntiFam along with additional custom-made families of spurious ORFs. This resource currently contains 23 families that identified 1310 spurious proteins in UniProtKB and a further 4119 spurious proteins in a collection of metagenomic sequences. UniProt has adopted AntiFam as a part of the UniProtKB quality control process and will investigate these spurious proteins for exclusion.
随着基因组 DNA 序列的大量涌现,经过人工整理的蛋白质序列所占的比例下降了。反过来,随着越来越多的实验室具备高通量测序的能力,这些实验室在准确识别和注释基因组内所有基因方面的信息能力可能常常不足。这些问题导致人们担心传递性注释错误会使序列数据库变得不可靠。在 Pfam 蛋白质家族数据库的生命周期中,已经构建了许多蛋白质家族,后来发现它们仅由虚假的开放阅读框 (ORF) 组成,这些 ORF 要么位于相反的链上,要么相对于真正的蛋白质编码或非编码 RNA 基因以不同的重叠阅读框存在。这些家族已被删除,不再可用于 Pfam。然而,我们意识到这些家族可能具有识别新的虚假 ORF 的有用功能。我们已经将这些家族与其他定制的虚假 ORF 家族一起收集在 AntiFam 中。该资源目前包含 23 个家族,在 UniProtKB 中鉴定出了 1310 个虚假蛋白质,在一组宏基因组序列中鉴定出了另外 4119 个虚假蛋白质。UniProt 已将 AntiFam 作为 UniProtKB 质量控制过程的一部分,并将对这些虚假蛋白质进行排除调查。