Ju Meizhi, Short Andrea D, Thompson Paul, Bakerly Nawar Diar, Gkoutos Georgios V, Tsaprouni Loukia, Ananiadou Sophia
National Centre for Text Mining, School of Computer Science, The University of Manchester, Manchester, UK.
Faculty of Biology, Medicine and Health, The University of Manchester, Manchester, UK.
JAMIA Open. 2019 Apr 26;2(2):261-271. doi: 10.1093/jamiaopen/ooz009. eCollection 2019 Jul.
Chronic obstructive pulmonary disease (COPD) phenotypes cover a range of lung abnormalities. To allow text mining methods to identify pertinent and potentially complex information about these phenotypes from textual data, we have developed a novel annotated corpus, which we use to train a neural network-based named entity recognizer to detect fine-grained COPD phenotypic information.
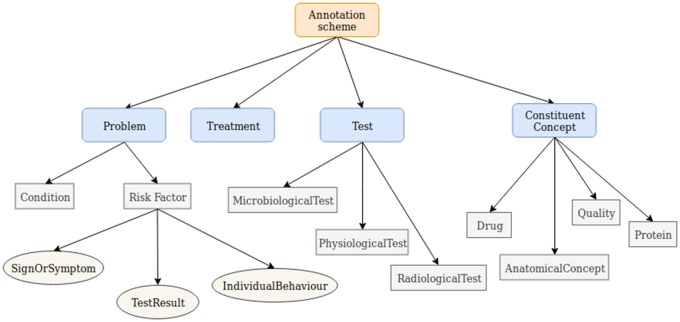
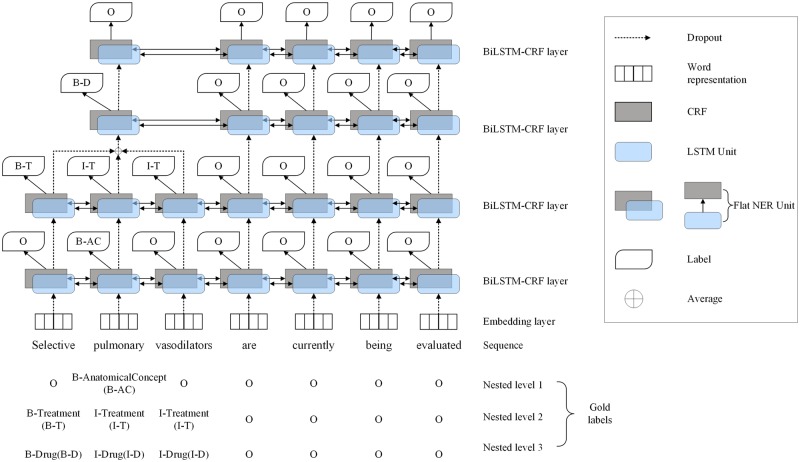
Since COPD phenotype descriptions often mention other concepts within them (proteins, treatments, etc.), our corpus annotations include both outermost phenotype descriptions and concepts nested within them. Our neural layered bidirectional long short-term memory conditional random field (BiLSTM-CRF) network firstly recognizes nested mentions, which are fed into subsequent BiLSTM-CRF layers, to help to recognize enclosing phenotype mentions.
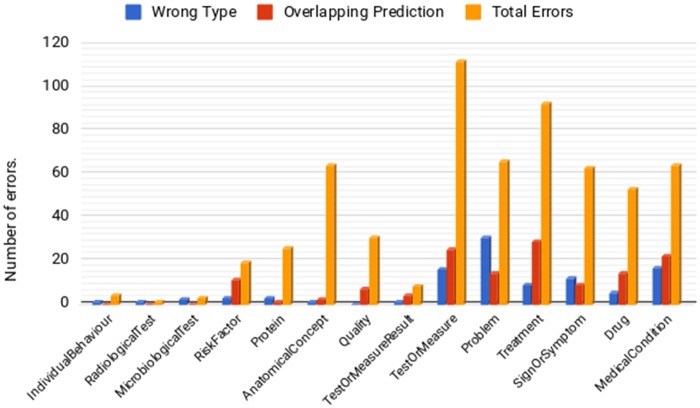
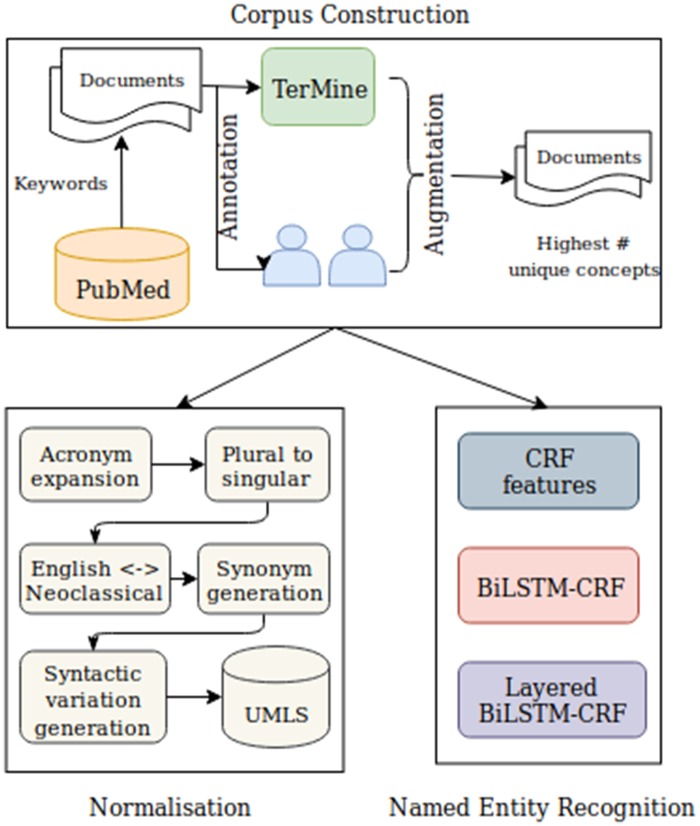
Our corpus of 30 full papers (available at: http://www.nactem.ac.uk/COPD) is annotated by experts with 27 030 phenotype-related concept mentions, most of which are automatically linked to UMLS Metathesaurus concepts. When trained using the corpus, our BiLSTM-CRF network outperforms other popular approaches in recognizing detailed phenotypic information.
Information extracted by our method can facilitate efficient location and exploration of detailed information about phenotypes, for example, those specifically concerning reactions to treatments.
The importance of our corpus for developing methods to extract fine-grained information about COPD phenotypes is demonstrated through its successful use to train a layered BiLSTM-CRF network to extract phenotypic information at various levels of granularity. The minimal human intervention needed for training should permit ready adaption to extracting phenotypic information about other diseases.
慢性阻塞性肺疾病(COPD)的表型涵盖一系列肺部异常情况。为了使文本挖掘方法能够从文本数据中识别有关这些表型的相关且可能复杂的信息,我们开发了一个新颖的注释语料库,并用其训练基于神经网络的命名实体识别器,以检测细粒度的COPD表型信息。
由于COPD表型描述中常常会提及其中包含的其他概念(蛋白质、治疗方法等),因此我们的语料库注释既包括最外层的表型描述,也包括嵌套在其中的概念。我们的神经分层双向长短期记忆条件随机场(BiLSTM-CRF)网络首先识别嵌套提及,这些嵌套提及会被输入到后续的BiLSTM-CRF层,以帮助识别包含这些提及的表型。
我们的30篇完整论文语料库(可在http://www.nactem.ac.uk/COPD获取)由专家注释了27030个与表型相关的概念提及,其中大部分已自动链接到UMLS元词表概念。当使用该语料库进行训练时,我们的BiLSTM-CRF网络在识别详细表型信息方面优于其他常用方法。
我们的方法提取的信息有助于高效定位和探索有关表型的详细信息,例如那些特别涉及对治疗反应的信息。
我们的语料库通过成功用于训练分层BiLSTM-CRF网络以提取不同粒度级别的表型信息,证明了其对于开发提取COPD表型细粒度信息方法的重要性。训练所需的最少人工干预应允许其易于适应提取有关其他疾病的表型信息。