Puccini Daniel, Liszkowski Ulf
Max Planck Research Group Communication before Language, Max Planck Institute for Psycholinguistics Nijmegen, Netherlands.
Front Psychol. 2012 Apr 3;3:101. doi: 10.3389/fpsyg.2012.00101. eCollection 2012.
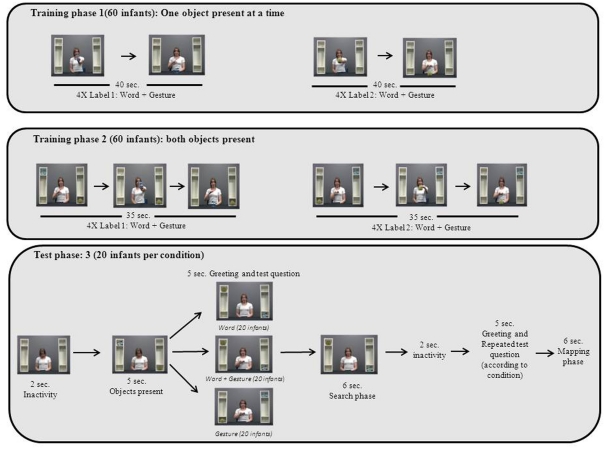
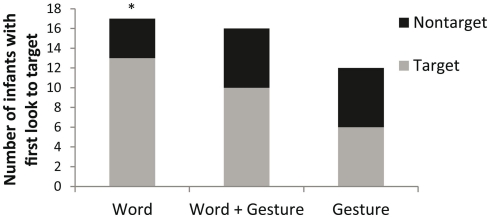
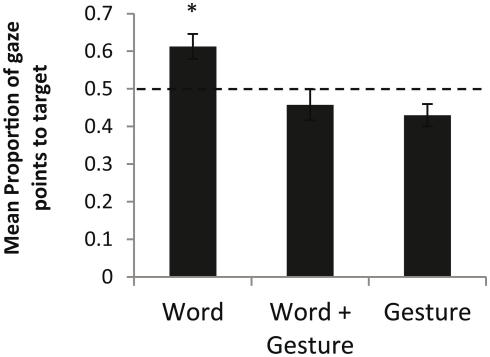
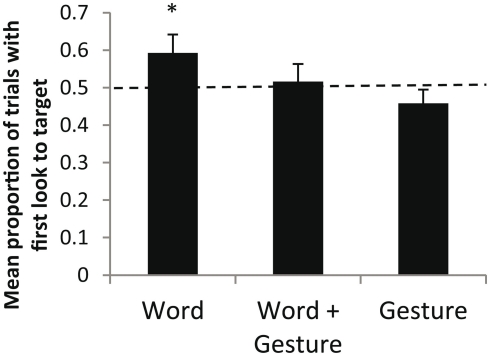
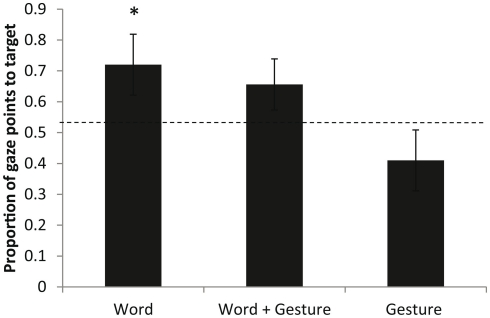
This study investigated whether 15-month-old infants fast map multimodal labels, and, when given the choice of two modalities, whether they preferentially fast map one better than the other. Sixty 15-month-old infants watched films where an actress repeatedly and ostensively labeled two novel objects using a spoken word along with a representational gesture. In the test phase, infants were assigned to one of three conditions: Word, Word + Gesture, or Gesture. The objects appeared in a shelf next to the experimenter and, depending on the condition, infants were prompted with either a word, a gesture, or a multimodal word-gesture combination. Using an infant eye tracker, we determined whether infants made the correct mappings. Results revealed that only infants in the Word condition had learned the novel object labels. When the representational gesture was presented alone or when the verbal label was accompanied by a representational gesture, infants did not succeed in making the correct mappings. Results reveal that 15-month-old infants do not benefit from multimodal labeling and that they prefer words over representational gestures as object labels in multimodal utterances. Findings put into question the role of multimodal labeling in early language development.
本研究调查了15个月大的婴儿是否能快速映射多模态标签,以及当面临两种模态的选择时,他们是否更倾向于快速映射其中一种。60名15个月大的婴儿观看了影片,片中一名女演员使用一个口语单词并伴随着一个表征性手势反复且明显地标记两个新物体。在测试阶段,婴儿被分配到三种条件之一:单词、单词+手势或手势。物体出现在实验者旁边的架子上,根据条件,婴儿会被提示一个单词、一个手势或一个单词-手势的多模态组合。使用婴儿眼动仪,我们确定婴儿是否做出了正确的映射。结果显示,只有处于单词条件下的婴儿学会了新物体标签。当单独呈现表征性手势或言语标签伴有表征性手势时,婴儿未能成功做出正确的映射。结果表明,15个月大的婴儿无法从多模态标签中受益,并且在多模态话语中,作为物体标签,他们更喜欢单词而非表征性手势。这些发现对多模态标签在早期语言发展中的作用提出了质疑。