European Bioinformatics Institute, Wellcome Trust Genome Campus, Hinxton, Cambridge, UK.
Nat Methods. 2012 Apr 27;9(5):459-62. doi: 10.1038/nmeth.1974.
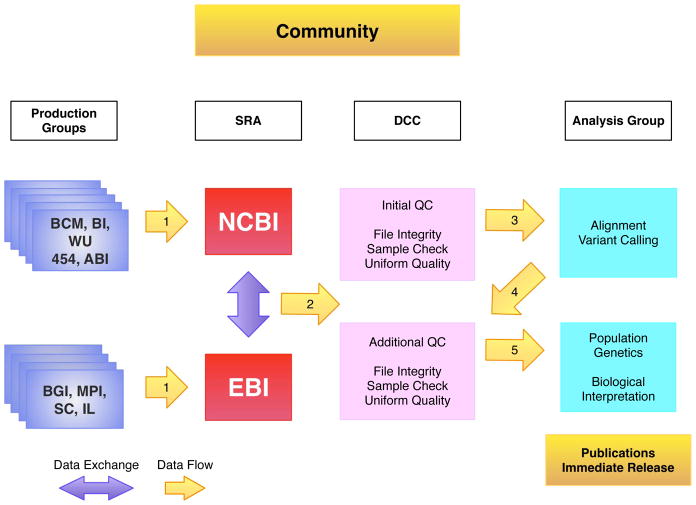
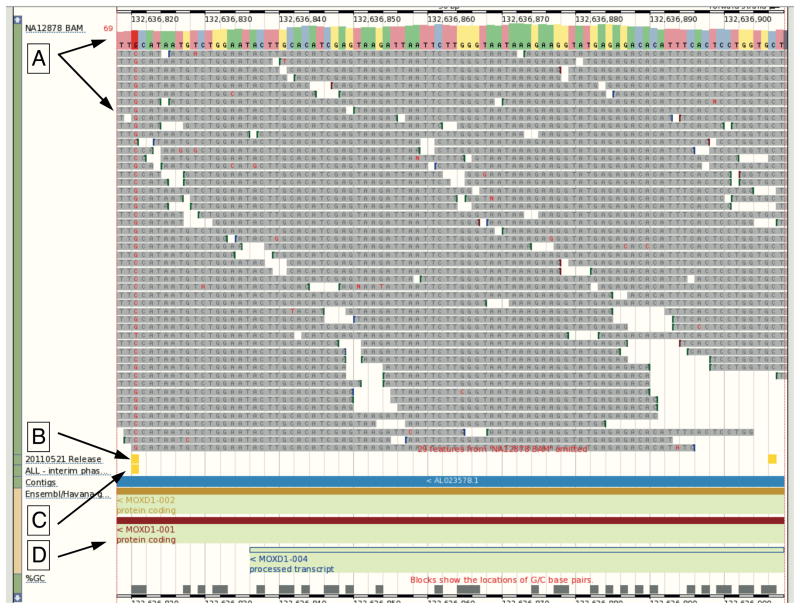
The 1000 Genomes Project was launched as one of the largest distributed data collection and analysis projects ever undertaken in biology. In addition to the primary scientific goals of creating both a deep catalog of human genetic variation and extensive methods to accurately discover and characterize variation using new sequencing technologies, the project makes all of its data publicly available. Members of the project data coordination center have developed and deployed several tools to enable widespread data access.
“千基因组计划”是生物学领域有史以来最大规模的分布式数据收集和分析项目之一。除了创建人类遗传变异深度目录和广泛使用新测序技术准确发现和描述变异的方法这两个主要科学目标外,该项目还公开提供其所有数据。项目数据协调中心的成员开发并部署了多个工具,以实现广泛的数据访问。