Guenther Frank H, Vladusich Tony
Department of Cognitive and Neural Systems, Boston University, 677 Beacon Street, Boston, MA, 02215.
J Neurolinguistics. 2012 Sep 1;25(5):408-422. doi: 10.1016/j.jneuroling.2009.08.006.
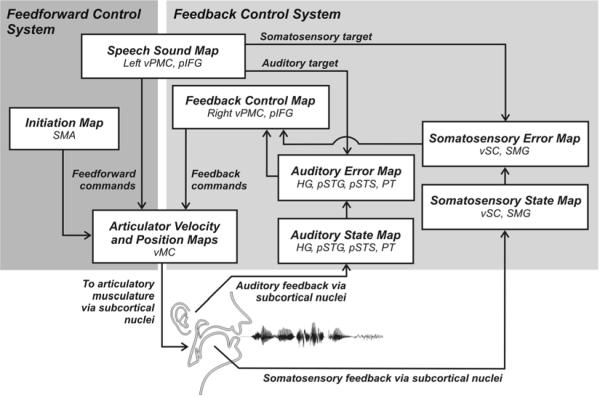
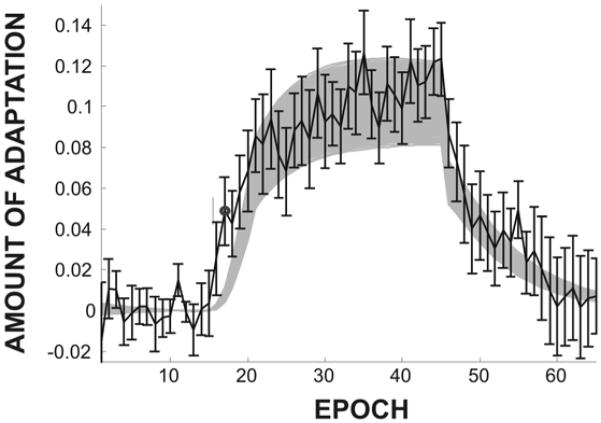
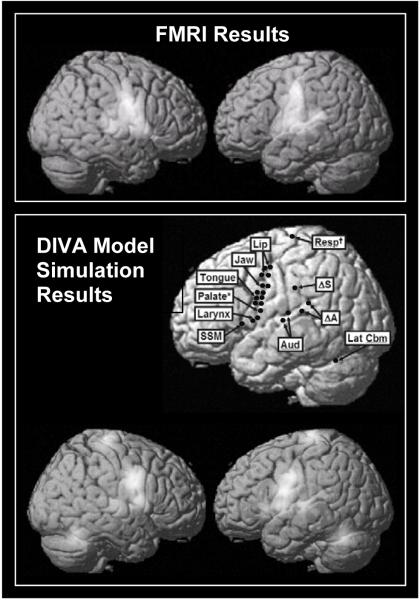
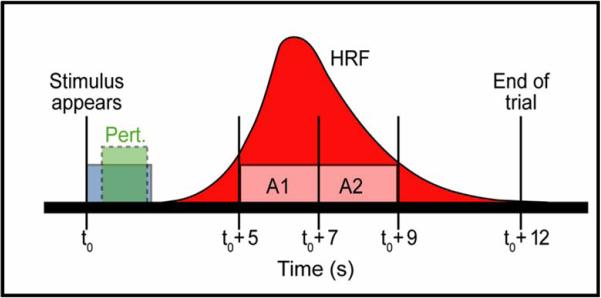
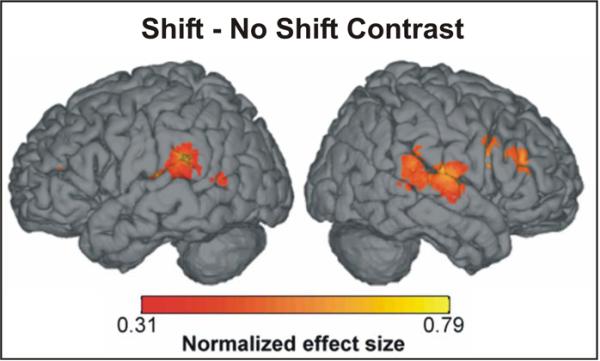
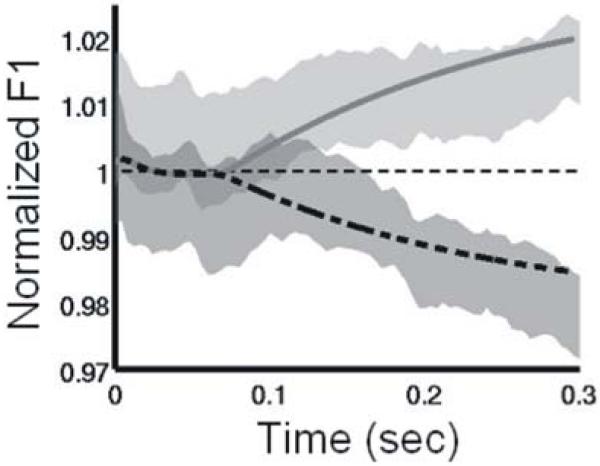
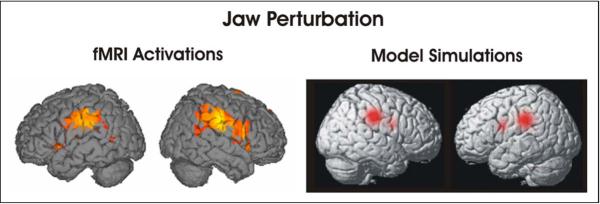
This article describes a computational model, called DIVA, that provides a quantitative framework for understanding the roles of various brain regions involved in speech acquisition and production. An overview of the DIVA model is first provided, along with descriptions of the computations performed in the different brain regions represented in the model. Particular focus is given to the model's speech sound map, which provides a link between the sensory representation of a speech sound and the motor program for that sound. Neurons in this map share with "mirror neurons" described in monkey ventral premotor cortex the key property of being active during both production and perception of specific motor actions. As the DIVA model is defined both computationally and anatomically, it is ideal for generating precise predictions concerning speech-related brain activation patterns observed during functional imaging experiments. The DIVA model thus provides a well-defined framework for guiding the interpretation of experimental results related to the putative human speech mirror system.
本文描述了一种名为DIVA的计算模型,该模型为理解参与语音习得和产生的各个脑区的作用提供了一个定量框架。首先介绍了DIVA模型的概况,以及在该模型所代表的不同脑区中执行的计算。特别关注了该模型的语音地图,它在语音的感官表征和该语音的运动程序之间提供了联系。这张地图中的神经元与猴子腹侧运动前皮层中描述的“镜像神经元”具有共同的关键特性,即在特定运动动作的产生和感知过程中都处于活跃状态。由于DIVA模型在计算和解剖学上都有明确的定义,因此非常适合生成关于在功能成像实验中观察到的与语音相关的脑激活模式的精确预测。因此,DIVA模型为指导对与假定的人类语音镜像系统相关的实验结果的解释提供了一个定义明确的框架。