Department of Computer Science, Stanford University, Stanford, CA, USA.
BMC Bioinformatics. 2012 Jun 26;13 Suppl 11(Suppl 11):S9. doi: 10.1186/1471-2105-13-S11-S9.
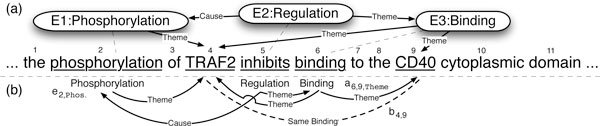
We explore techniques for performing model combination between the UMass and Stanford biomedical event extraction systems. Both sub-components address event extraction as a structured prediction problem, and use dual decomposition (UMass) and parsing algorithms (Stanford) to find the best scoring event structure. Our primary focus is on stacking where the predictions from the Stanford system are used as features in the UMass system. For comparison, we look at simpler model combination techniques such as intersection and union which require only the outputs from each system and combine them directly.
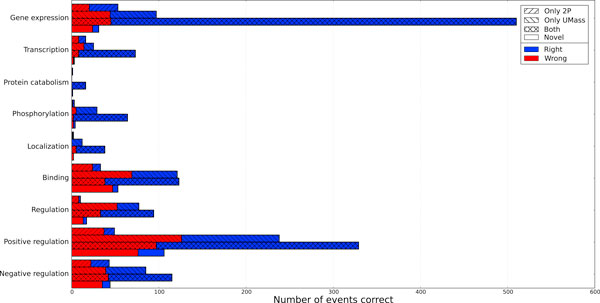
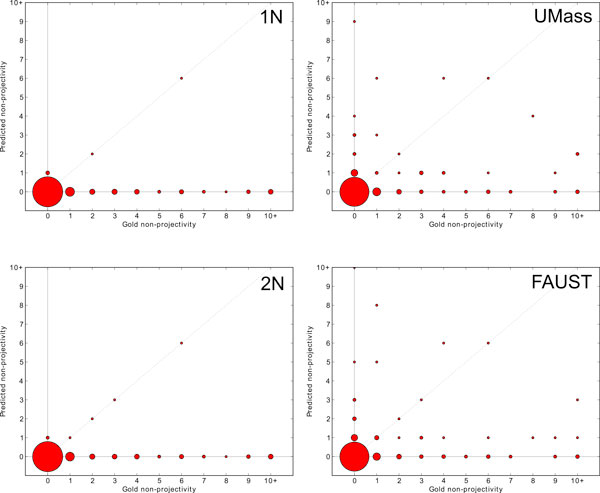
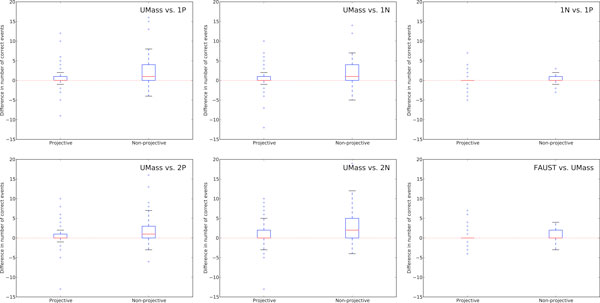
First, we find that stacking substantially improves performance while intersection and union provide no significant benefits. Second, we investigate the graph properties of event structures and their impact on the combination of our systems. Finally, we trace the origins of events proposed by the stacked model to determine the role each system plays in different components of the output. We learn that, while stacking can propose novel event structures not seen in either base model, these events have extremely low precision. Removing these novel events improves our already state-of-the-art F1 to 56.6% on the test set of Genia (Task 1). Overall, the combined system formed via stacking ("FAUST") performed well in the BioNLP 2011 shared task. The FAUST system obtained 1st place in three out of four tasks: 1st place in Genia Task 1 (56.0% F1) and Task 2 (53.9%), 2nd place in the Epigenetics and Post-translational Modifications track (35.0%), and 1st place in the Infectious Diseases track (55.6%).
We present a state-of-the-art event extraction system that relies on the strengths of structured prediction and model combination through stacking. Akin to results on other tasks, stacking outperforms intersection and union and leads to very strong results. The utility of model combination hinges on complementary views of the data, and we show that our sub-systems capture different graph properties of event structures. Finally, by removing low precision novel events, we show that performance from stacking can be further improved.
我们探索了在 UMass 和斯坦福生物医学事件抽取系统之间进行模型组合的技术。这两个子组件都将事件抽取视为一个结构化预测问题,并使用对偶分解(UMass)和解析算法(斯坦福)来找到最佳评分的事件结构。我们的主要关注点是堆叠,其中斯坦福系统的预测被用作 UMass 系统的特征。为了进行比较,我们还研究了更简单的模型组合技术,例如交集和并集,它们只需要每个系统的输出,并直接对其进行组合。
首先,我们发现堆叠可以极大地提高性能,而交集和并集则没有明显的好处。其次,我们研究了事件结构的图属性及其对我们系统组合的影响。最后,我们追溯了堆叠模型提出的事件的起源,以确定每个系统在输出的不同组件中所扮演的角色。我们发现,虽然堆叠可以提出在任何一个基础模型中都没有看到的新的事件结构,但这些事件的精度极低。去除这些新的事件可以将我们已经处于最先进水平的 F1 提高到 Genia(任务 1)测试集的 56.6%。总体而言,通过堆叠形成的组合系统(“FAUST”)在 BioNLP 2011 共享任务中表现出色。FAUST 系统在四个任务中的三个任务中获得了第一名:Genia 任务 1(56.0% F1)和任务 2(53.9%)、表观遗传学和翻译后修饰跟踪(35.0%),以及传染病跟踪(55.6%)。
我们提出了一种基于结构化预测和通过堆叠进行模型组合的最先进的事件抽取系统。与其他任务的结果类似,堆叠的性能优于交集和并集,并取得了非常出色的结果。模型组合的效用取决于对数据的互补观点,我们表明我们的子系统捕捉到了事件结构的不同图属性。最后,通过去除低精度的新颖事件,我们表明堆叠的性能可以进一步提高。