Kordjamshidi Parisa, Roth Dan, Moens Marie-Francine
KULeuven, Leuven, Belgium.
University of Illinois at Urbana-Champaign, Urbana-Champaign, USA.
BMC Bioinformatics. 2015 Apr 25;16:129. doi: 10.1186/s12859-015-0542-z.
We aim to automatically extract species names of bacteria and their locations from webpages. This task is important for exploiting the vast amount of biological knowledge which is expressed in diverse natural language texts and putting this knowledge in databases for easy access by biologists. The task is challenging and the previous results are far below an acceptable level of performance, particularly for extraction of localization relationships. Therefore, we aim to design a new system for such extractions, using the framework of structured machine learning techniques.
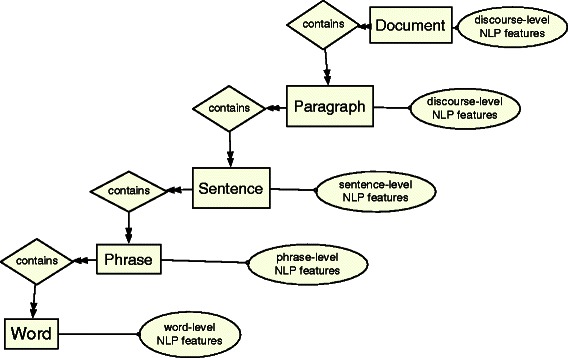
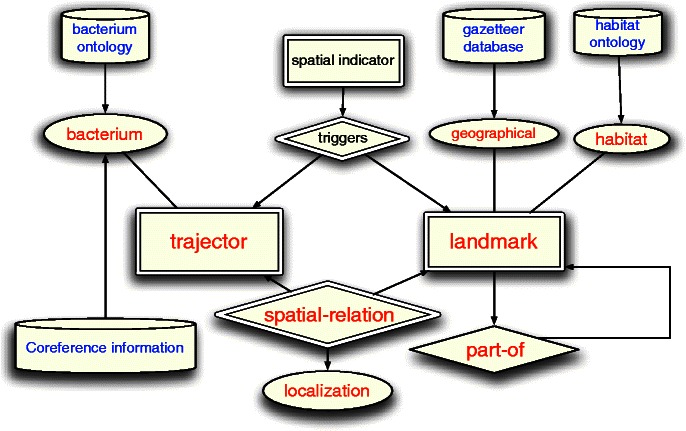
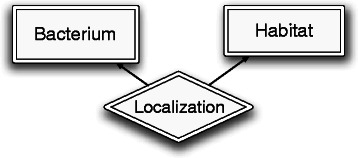
We design a new model for joint extraction of biomedical entities and the localization relationship. Our model is based on a spatial role labeling (SpRL) model designed for spatial understanding of unrestricted text. We extend SpRL to extract discourse level spatial relations in the biomedical domain and apply it on the BioNLP-ST 2013, BB-shared task. We highlight the main differences between general spatial language understanding and spatial information extraction from the scientific text which is the focus of this work. We exploit the text's structure and discourse level global features. Our model and the designed features substantially improve on the previous systems, achieving an absolute improvement of approximately 57 percent over F1 measure of the best previous system for this task.
Our experimental results indicate that a joint learning model over all entities and relationships in a document outperforms a model which extracts entities and relationships independently. Our global learning model significantly improves the state-of-the-art results on this task and has a high potential to be adopted in other natural language processing (NLP) tasks in the biomedical domain.
我们旨在从网页中自动提取细菌的物种名称及其位置。这项任务对于利用大量以各种自然语言文本表达的生物学知识,并将这些知识存入数据库以便生物学家轻松访问而言非常重要。该任务具有挑战性,且先前的结果远低于可接受的性能水平,尤其是在提取定位关系方面。因此,我们旨在使用结构化机器学习技术框架设计一个用于此类提取的新系统。
我们设计了一种用于联合提取生物医学实体及其定位关系的新模型。我们的模型基于为理解无限制文本的空间信息而设计的空间角色标注(SpRL)模型。我们扩展了SpRL以提取生物医学领域中的篇章级空间关系,并将其应用于BioNLP - ST 2013的BB共享任务。我们强调了一般空间语言理解与从科学文本中提取空间信息之间的主要差异,而科学文本正是本工作的重点。我们利用了文本的结构和篇章级全局特征。我们的模型和所设计的特征在先前系统的基础上有了显著改进,相对于此任务中先前最佳系统的F1值,绝对提升了约57%。
我们的实验结果表明,对文档中所有实体和关系进行联合学习的模型优于独立提取实体和关系的模型。我们的全局学习模型显著改进了该任务的当前最优结果,并且在生物医学领域的其他自然语言处理(NLP)任务中具有很高的应用潜力。