Radboud University of Nijmegen, the Netherlands.
Brief Bioinform. 2013 May;14(3):315-26. doi: 10.1093/bib/bbs034. Epub 2012 Jul 10.
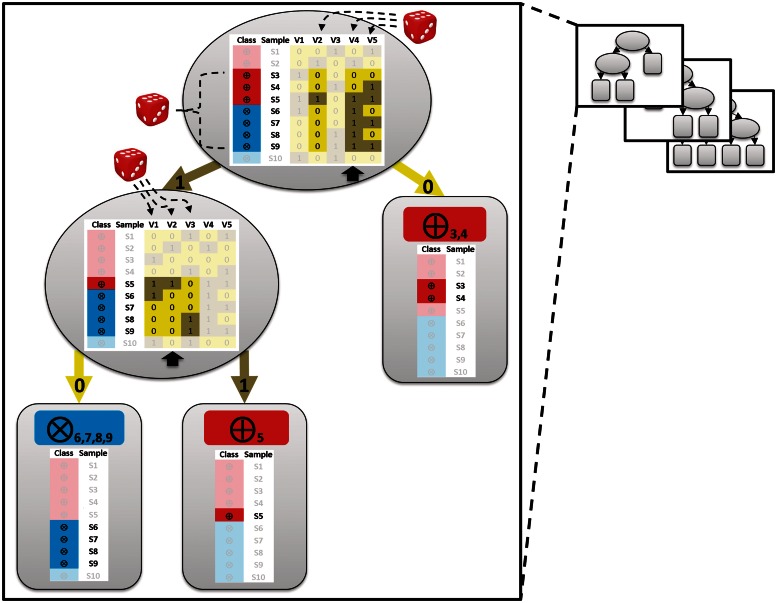
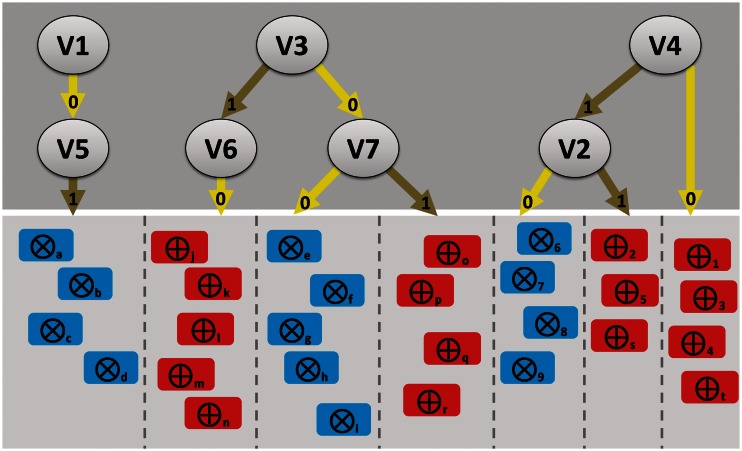
In the Life Sciences 'omics' data is increasingly generated by different high-throughput technologies. Often only the integration of these data allows uncovering biological insights that can be experimentally validated or mechanistically modelled, i.e. sophisticated computational approaches are required to extract the complex non-linear trends present in omics data. Classification techniques allow training a model based on variables (e.g. SNPs in genetic association studies) to separate different classes (e.g. healthy subjects versus patients). Random Forest (RF) is a versatile classification algorithm suited for the analysis of these large data sets. In the Life Sciences, RF is popular because RF classification models have a high-prediction accuracy and provide information on importance of variables for classification. For omics data, variables or conditional relations between variables are typically important for a subset of samples of the same class. For example: within a class of cancer patients certain SNP combinations may be important for a subset of patients that have a specific subtype of cancer, but not important for a different subset of patients. These conditional relationships can in principle be uncovered from the data with RF as these are implicitly taken into account by the algorithm during the creation of the classification model. This review details some of the to the best of our knowledge rarely or never used RF properties that allow maximizing the biological insights that can be extracted from complex omics data sets using RF.
在生命科学领域,越来越多的“组学”数据是由不同的高通量技术产生的。通常,只有整合这些数据才能揭示可以通过实验验证或通过机制建模来证实的生物学见解,也就是说,需要复杂的计算方法来提取组学数据中存在的复杂非线性趋势。分类技术允许根据变量(例如遗传关联研究中的 SNPs)训练模型,以分离不同的类别(例如健康受试者与患者)。随机森林(RF)是一种通用的分类算法,适用于这些大型数据集的分析。在生命科学中,RF 很受欢迎,因为 RF 分类模型具有很高的预测准确性,并提供了有关变量对分类重要性的信息。对于组学数据,变量或变量之间的条件关系通常对同一类别的样本子集很重要。例如:在癌症患者的一个类别中,某些 SNP 组合对于具有特定癌症亚型的患者子集可能很重要,但对于不同患者子集则不重要。这些条件关系原则上可以从数据中使用 RF 揭示出来,因为在创建分类模型时,算法会自动考虑这些关系。本综述详细介绍了一些据我们所知很少或从未使用过的 RF 属性,这些属性允许从复杂的组学数据集提取最大的生物学见解。