The Exelixis Lab, Scientific Computing Group, Heidelberg Institute for Theoretical Studies, Germany.
BMC Bioinformatics. 2012 Aug 9;13:196. doi: 10.1186/1471-2105-13-196.
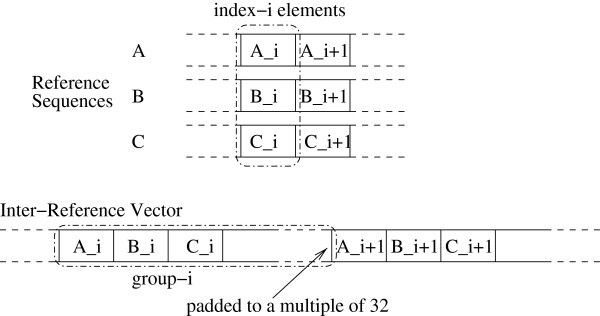
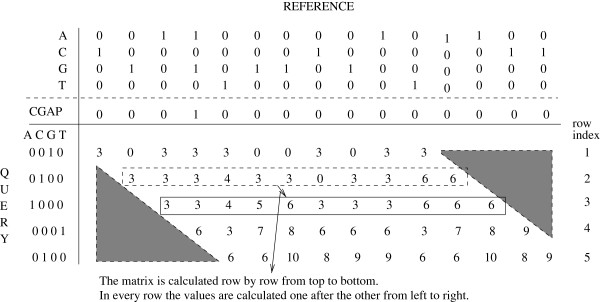
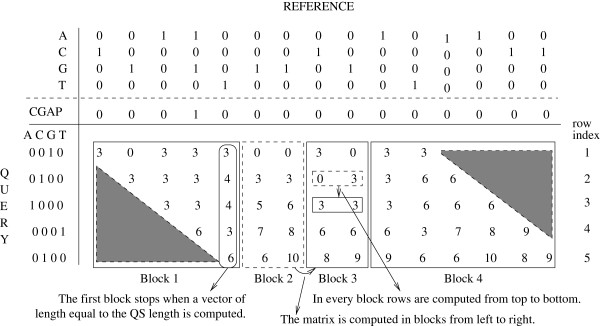
Aligning short DNA reads to a reference sequence alignment is a prerequisite for detecting their biological origin and analyzing them in a phylogenetic context. With the PaPaRa tool we introduced a dedicated dynamic programming algorithm for simultaneously aligning short reads to reference alignments and corresponding evolutionary reference trees. The algorithm aligns short reads to phylogenetic profiles that correspond to the branches of such a reference tree. The algorithm needs to perform an immense number of pairwise alignments. Therefore, we explore vector intrinsics and GPUs to accelerate the PaPaRa alignment kernel.
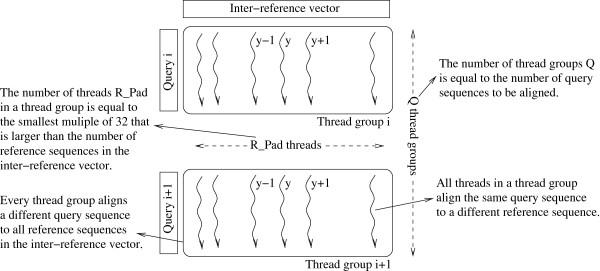
We optimized and parallelized PaPaRa on CPUs and GPUs. Via SSE 4.1 SIMD (Single Instruction, Multiple Data) intrinsics for x86 SIMD architectures and multi-threading, we obtained a 9-fold acceleration on a single core as well as linear speedups with respect to the number of cores. The peak CPU performance amounts to 18.1 GCUPS (Giga Cell Updates per Second) using all four physical cores on an Intel i7 2600 CPU running at 3.4 GHz. The average CPU performance (averaged over all test runs) is 12.33 GCUPS. We also used OpenCL to execute PaPaRa on a GPU SIMT (Single Instruction, Multiple Threads) architecture. A NVIDIA GeForce 560 GPU delivered peak and average performance of 22.1 and 18.4 GCUPS respectively. Finally, we combined the SIMD and SIMT implementations into a hybrid CPU-GPU system that achieved an accumulated peak performance of 33.8 GCUPS.
This accelerated version of PaPaRa (available at http://www.exelixis-lab.org/software.html) provides a significant performance improvement that allows for analyzing larger datasets in less time. We observe that state-of-the-art SIMD and SIMT architectures deliver comparable performance for this dynamic programming kernel when the "competing programmer approach" is deployed. Finally, we show that overall performance can be substantially increased by designing a hybrid CPU-GPU system with appropriate load distribution mechanisms.
将短 DNA 读取与参考序列比对是检测其生物起源并在系统发生背景下分析它们的前提。使用 PaPaRa 工具,我们引入了一种专门的动态规划算法,用于同时将短读取与参考比对和相应的进化参考树进行比对。该算法将短读取与对应于参考树分支的系统发生分布进行比对。该算法需要执行大量的两两比对。因此,我们探索了矢量内在函数和 GPU 来加速 PaPaRa 比对核心。
我们在 CPU 和 GPU 上对 PaPaRa 进行了优化和并行化。通过 x86 SIMD(单指令,多数据)内在函数和多线程,我们在单个核心上获得了 9 倍的加速,并且相对于核心数量具有线性加速。在一个运行频率为 3.4GHz 的 Intel i7 2600 CPU 上,使用所有四个物理核心,峰值 CPU 性能达到 18.1 GCUPS(每秒十亿个细胞更新)。平均 CPU 性能(在所有测试运行中平均)为 12.33 GCUPS。我们还使用 OpenCL 在 GPU SIMT(单指令,多线程)架构上执行 PaPaRa。NVIDIA GeForce 560 GPU 提供了峰值和平均性能,分别为 22.1 和 18.4 GCUPS。最后,我们将 SIMD 和 SIMT 实现组合到一个混合 CPU-GPU 系统中,实现了 33.8 GCUPS 的累积峰值性能。
此加速版本的 PaPaRa(可在 http://www.exelixis-lab.org/software.html 上获得)提供了显著的性能提升,允许在更短的时间内分析更大的数据集。我们观察到,当采用“竞争程序员方法”时,最先进的 SIMD 和 SIMT 架构为这个动态规划内核提供了相当的性能。最后,我们表明,通过设计具有适当负载分配机制的混合 CPU-GPU 系统,可以大大提高整体性能。